
AWS: Cloud 101
An introduction to AWS and how cloud has changed computing.
info

To access material, start machines and answer questions login.
Learning Objectives
This room is intended to provide users who are not familiar with cloud technologies insight into some of the cloud's unique characteristics. Students in the room will learn about:
- How current cloud capabilities evolved from humble beginnings at and other early internet companies.
- Why cloud technologies have changed how individuals and corporations interact with IT infrastructure.
- How business (non-tech) benefits have helped drive cloud adoption.
- Free resources and documentation that has created for the public.
This information will help you become familiar with even if you have never used a single cloud technology. These tasks will help you understand the broader story arc of where the cloud has been, is, and, therefore...where the cloud may be going.
On-premise Model
Organizations have been hosting their own IT infrastructure in one form or another since the 1970s. But during the late 1990s "Dot-com" boom, organizations began to have widespread business reliance on internet-connected services. To serve these needs, companies drastically expanded their data center footprints. As the data center business grew, it became common for third parties to manage data centers on behalf of their customers.
"The Cloud"
At first, the "cloud" often meant hosting servers in someone else's data center. Rather than manage a fleet of servers (running 24/7) with a bare-bones IT department at a small or medium-sized company, organizations would offload this responsibility to a third-party provider who specializes in managing IT infrastructure. Eventually, providers developed custom software to manage the large fleets of infrastructure (networking gear and servers) that had been deployed. While perceptions persisted for some time that the cloud was just "someone else's computer", this room is designed to cover some of the unique characteristics of "cloud" providers, and specifically - .
Growing Demands
Starting in the late 1990s (opens in new tab), websites could not handle the traffic coming their way from the ever-growing "world wide web". As the 2000s started, a number of technologies came onto the scene to address these needs. First, there were content delivery networks (CDNs), that would serve static content on behalf of a website. Then along came , a lab machine service that would allow customers to deploy additional servers on-demand.

Evolving Approach
While originally a simple service designed for customers to leverage a pool of additional server capacity, the programmatic nature of deployment (opens in new tab) allowed developers to create automated scaling workflows that were the early predecessor to Autoscaling. While third-parties initially created "autoscaling (opens in new tab)" services, released the official autoscaling feature for in 2009. Leveraging autoscaling, a customer can specify how to scale infrastructure in response to a wide variety of static and dynamic conditions. Though it may not seem significant, this change dramatically improved technology teams' ability to manage operational costs and improve flexibility under changing demands.
Since and Autoscaling, has created a number of services that further enable scalability. Technologies that support "cloud-native" architecture are a key component of 's strategy. While this training won't go in-depth on cloud-native concepts such as "containerization (opens in new tab)" and "serverless (opens in new tab)" capabilities, you should have a general idea of what these are and that they represent additional building blocks that help create highly-scalable infrastructure.
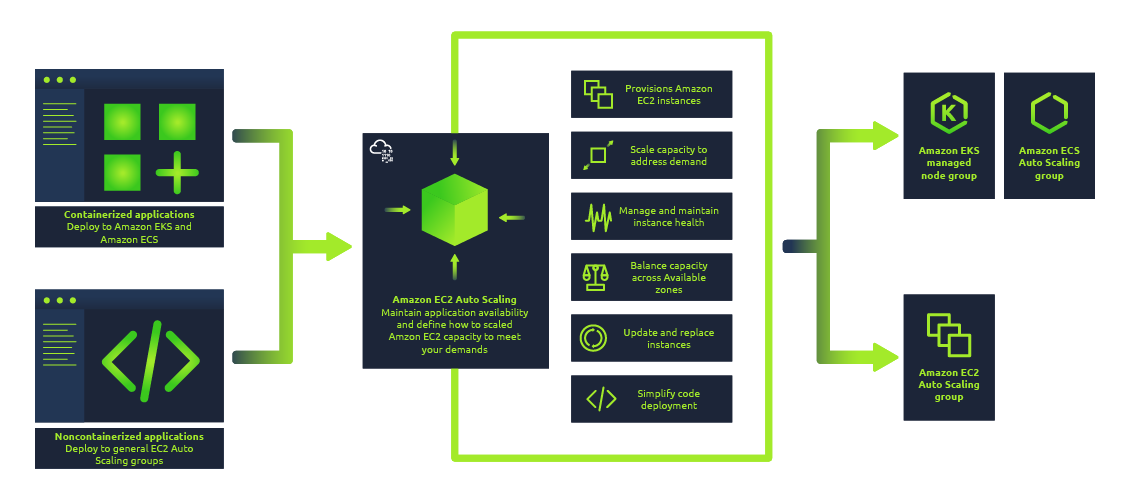
Autoscaling allows scaling any type of application (containerized or noncontainerized) and maintains application availability to meet customers' demands.
Legacy On-Premise Pattern
Prior to the cloud, failover capabilities for data centers were often manual and highly customized for the technology stack of a particular organization. This often took the form of a primary and backup data center that were geographically separated, using a common virtualization infrastructure (e.g., VMWare, etc.) that was replicated in both locations. However, organizations were forced to spend a substantial amount of time and energy trying to gracefully "failover" between data centers or risk a prolonged outage in the event that a primary data center outage occurred and failover attempts to the secondary data center were unsuccessful. Furthermore, organizations had to maintain a backup data center and the eye-popping associated costs, only for it to sit idle for extended periods of time.
Cloud Patterns
and other “hyper-scale” cloud providers have a distinct advantage in reliability for a number of reasons. One key reason is that runs a large number of data centers, which means that they can gather data and insights about the failure of their systems that would not be feasible for most organizations with only one or a handful of data centers. While specific numbers are not clear regarding the number of data centers, claims to have 99 "availability zones" in over 31 "regions" (opens in new tab) (at the time of writing).
Let's unpack what that means:
Region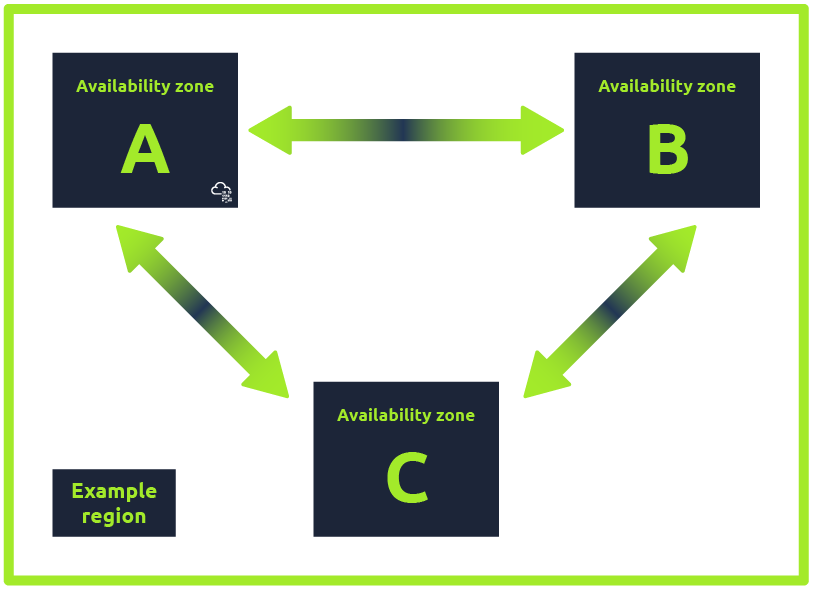
defines a "region" as "a physical location around the world where we cluster data centers." (opens in new tab) A region will be made up of one or more "availability zones." These data centers that make up an availability zone will all be located within 60 miles of each other in the given region. Though not every service is available in each region, and some services are not bound to a specific region, architecture is designed so that most services are available across a wide number of regions (opens in new tab). Not all services are regional, some global (opens in new tab)like Amazon Route 53, Manager, etc.
Availability Zone
An Availability Zone (AZ) is one or more discrete data centers with redundant power, networking, and connectivity in an Region. These separations mean that an outage of one AZ due to lost power, networking issues, or ISP connectivity issues should not affect any other AZ. further intends for availability zones to be the key failover capability required by end-customers. In fact, during this (opens in new tab) 2018 ReInvent ( annual conference) talk, the speaker highlights how " regional services are designed to withstand AZ failures." While this perspective has been challenged by real-world experience (opens in new tab), applications built on are generally considered to be highly resilient if deployed in a multi-AZ configuration. The above figure illustrates that a single region can contain multiple availability zones.
You can recognize an availability zone based on the letter following a region name when working with Virtual Private Cloud () bound resources. For example, US-East-1 has the following availability zones:
- us-east-1a
- us-east-1b
- us-east-1c
- us-east-1d
- us-east-1e
- us-east-1f
Naming Conventions
Perhaps you have generalized naming conventions from the examples above. For those who don't see the pattern, names regions and availability zones are based on a common naming convention. For regions, names commonly start with one of a few different designations:
- af (Africa)
- ap (Asia Pacific)
- (Canada)
- eu (Europe)
- me (Middle East)
- sa (South America)
- us (United States)
A cardinal direction (North, South, East, West, Central) or a combination (SouthEast, NorthWest) is appended to the abbreviation based on where the region is inside of the geography of the region (e.g., us-east for those data centers considered to be in the eastern USA). The convention follows with a numerical designation (1, 2, 3, etc.) based on whether it is the first, second, third, etc. region within the geographic location.
For example, af-south-1 is located in Cape Town, South Africa. It is a region on the African continent (af), in the southern portion of that geographic area (south), and the first such region (1). There are other designations that are less common such as US GovCloud, and those associated with China, but the general naming convention can provide you with helpful context as you use .
Data Sovereignty
On August 25th of 2006, launched in the US-East-1 region located in Northern Virginia. A short 15 months later, launched a European version of object storage (opens in new tab)due to the need of European customers to keep data in Europe. This was the beginning of a common theme and an important concept to understand about cloud technology. While customers in the US have enjoyed the benefits of since the beginning, other countries may have "data sovereignty" laws or regulations that dictate which region will host their companies' technology assets or even whether the associated data can be hosted in the cloud at all.
At present, hosts Regions on every continent except Antarctica and in many key locations with data sovereignty requirements. Notably, China is even a separate "partition" (-cn) which means that China accounts are managed entirely apart from other global accounts (opens in new tab). also maintains separate partitions for USA GovCloud (-us-gov), USA government secret data (-iso), and USA government top secret data (-iso-b). While these are the known partitions, there are likely others, including internal partition(s).
Latency
Beyond the hard requirement of data sovereignty, geo-distribution serves the dual benefit of allowing customers to host internet-facing resources in a geographic location near where customers will be at the time of access. Even though data travels through fiber optic cables at nearly the speed of light, latency can increase dramatically over physical distance (opens in new tab). This is additionally important due to search engine considerations about site latency, where search engines are a primary driver of traffic for many sites. Sites that consistently exhibit poor latency are unlikely to receive high search engine rankings.
customers may take advantage of geo-distribution in a number of ways, but one notable way is through the use of , the Content Delivery Network (CDN). has over 275 "Point-of-Presences", where a "Point-of-Presence" is a physical location serving internet traffic. enables intelligent traffic routing and caching for end user requests with minimal configuration by the customer.
Finally, the region concept raised in the previous task provides an ability to geo-distribute workloads by strategically deploying applications/workloads in regions that are anticipated to have high end user traffic. service Route53 allows customers to route traffic (opens in new tab) based on traffic geo-location. In combination with Elastic Load Balancers (ELBs), this can allow customers to ensure they're serving non-static resources with as little latency as possible.
What continent has no AWS Region?
Cloud: A Business Solution
While this course is focused on security associated with - it is important to also understand the business value of cloud vs. on-premise data centers. After all, companies only use technology so that they can make money. A key concept to understand related to the business value of the cloud is the notion of capital (CapEx) vs. operational (OpEx) expenses.
CapEx vs. OpEx
In business, a capital expense is a major purchase of goods or services intended to be used by a company over a long period of time. In contrast, operating expenses are expenses incurred as part of day-to-day operations. In the past, organizations were known to pay in excess of $1,000 per square foot for data center build-out and configuration. Using that pricing, a 1,000 square foot (304m) data center would cost USD 1m. With the expensive nature of data centers, cloud providers saw an opportunity to create a different approach. Essentially, every wasted compute cycle represents poor investment dollars spent. The inefficiency was dramatic when calculated across industries.
At "hyper-scale", as cloud provider environments are called, cost and operational efficiencies are inherent relative to any specific company building a data center for internal company use. Cloud allows a pay-as-you-go and reserved capacity model to better manage IT expenses relative to the organization's IT needs. Furthermore, cloud highly optimizes workloads for efficiency ("bin-packing"), virtualization management, networking "tricks (opens in new tab)", etc., resulting in more efficient operating costs that can be passed on to end customers.
Finally, only spending money on assets that are currently in use has the advantage of enhancing operational agility. Rather than be committed to the sunk cost of CapEx, cloud providers allow organizations to change the size and types of technologies in use based on today's business needs - not based on decisions made 5 years ago, by a different group of business and IT leaders.
The Mandate
Even prior to the formation of , the CEO of Amazon, Jeff Bezos, issued a mandate across Amazon that internal teams would be required to make their data accessible to all other teams via a service interface (). As the legend goes, the specific mandate stated the following:
1. All teams will henceforth expose their data and functionality through service interfaces.
2. Teams must communicate with each other through these interfaces.
3. There will be no other form of interprocess communication allowed: no direct linking, no direct reads of another team’s data store, no shared-memory model, no back-doors whatsoever. The only communication allowed is via service interface calls over the network.
4. It doesn’t matter what technology they use. , Corba, Pubsub, custom protocols — doesn’t matter.
5. All service interfaces, without exception, must be designed from the ground up to be externalizable. That is to say, the team must plan and design to be able to expose the interface to developers in the outside world. No exceptions.
6. Anyone who doesn’t do this will be fired.
7. Thank you; have a nice day! (Bezos, 2002).
This integrated approach to data management provided the key to 's early success. It turned out that creating standardized APIs to interact with services and resources is the key capability to unlock automation for customers. Because teams always had to plan for external customers to use their services, customers rapidly benefit from the unique capabilities develops. Any customers who interact with services are ultimately interacting with service APIs, in many cases - the very same APIs that employees use.
The Two Pizza Team
Jeff Bezos commonly encourages his perspective across , with both positive and negative effects. Another such example is the "Two Pizza Team" rule. Bezos famously stated as claiming, "We try not to create teams larger than can be fed by two pizzas". The reasoning cited was that smaller teams foster collaboration. While it is true that this collaboration likely led to much of the innovation we appreciate from today, it also had another effect.
has over 300 services today, and each of those services is run by a different team. When developing APIs (and naming conventions), consistency is key to usability for end users. Unfortunately, with the various teams, there is a lot of variety in the naming convention of service APIs. When using services that may have similar capabilities, end users can't rely on those APIs being consistently named. With the need to be precise with programming grammar, these inconsistencies can leave developers frustrated and extensive digging through service documentation.
Built-in Advantage
When you use - you have access to a large number of services pre-configured to get you up and running quickly. Whether your need is a website, a database, or a Continuous Integration / Continuous Delivery pipeline - already has capabilities ready to go for you. But beyond the services themselves, has made large contributions (opens in new tab) to the open source software (OSS) space. These contributions include a wide variety of tools to enable services, along with pre-built solutions to general business IT problems.
To use an example, CloudFormation is an "Infrastructure-as-Code" (IaC) service that allows users to deploy complex resources into an account using pre-defined or templates. Beyond providing the service itself, provides reference implementations (opens in new tab) and sample templates (opens in new tab) for various services that users can take and customize or adopt as-is. This goes so far as to include a fully functional airline booking application (opens in new tab) developed by that you can deploy in your own account, so if you happen to start your own airline - you can be up and running in no time.
Service Tools
One notable type of OSS offered by is ecosystem tools. Ecosystem tools are tools that has created to help users with the service ecosystem, and include things like -data-wrangler (opens in new tab) (advertised as Python Pandas for services), -shell (opens in new tab) (integrated ), and --powertools-python (opens in new tab) (enhances functionality). As these tools and capabilities are not widely advertised, customers may not be familiar with many or all of their capabilities. However, as an user - you should research and be aware of services and example code before attempting to develop custom capabilities.
Genesis of Serverless
When created (Simple Storage Service) in 2006, few could have foreseen the shift in approach it would facilitate. Services like (an object/blob storage service), DynamoDB (a database service), and (a notification service) dramatically reduced the effort spent on initial configuration and ongoing management of IT infrastructure. Serverless also has the benefit of little to no operational cost when idle. This means that if users aren't accessing your application and performing activities, you can incur significantly less cost than with servers running at the same cost regardless of use. These benefits were immediately clear.
However, the serverless capabilities that has brought into existence since then provide integrations and capabilities that would have been hard to foresee back in 2006. Today - organizations that use have access to a wide variety of serverless services (opens in new tab), with a vast range of support tools and reference implementations. For a developer, there are a few ways to go from an initial idea to a functional, scalable, and publicly accessible application faster than using serverless capabilities.
Low-code/No-code Solutions
Beyond pioneering a wide range of "serverless" capabilities, also developed "low-code/no-code" services. These services allow developers, and in some cases, users without programming skills, to develop custom code and capabilities in with minimal configuration. Honeycode (opens in new tab) is an example of a pure "no-code" solution, offering a drag-and-drop interface for building web applications and static websites. Amplify (opens in new tab) requires a bit more technical skill, but has become very popular for allowing developers to quickly build mobile and web applications.
These types of service offerings include a wide variety of other services beyond web and mobile applications. Services such as (opens in new tab) allow customers to build new applications and integrations based on custom or pre-existing application workflows. While still in the early stages, and other cloud providers are working to create software development workflows that don't inherently require programming skills.
During this room, you have learned some history about cloud technology and the basic benefits of using "the cloud". You should now understand:
- How technology limitations in the 1990s and 2000s drove the development of "cloud technologies".
- How capabilities associated with reliability and scalability are hallmarks of cloud service providers.
- How companies may see cost and IT agility benefits from using the cloud.
- How an first approach was powerful and also had drawbacks.
- How provides various services, capabilities, code, and documentation for free.
This background knowledge should serve as helpful context as you further explore cloud technologies, and specifically, our other rooms.
Ready to learn Cyber Security?
TryHackMe provides free online cyber security training to secure jobs & upskill through a fun, interactive learning environment.
Already have an account? Log in