AI Threat Modelling
Assess and mitigate enterprise AI/ML risks via systematic, defender-focused auditing.
medium

To access material, start machines and answer questions login.
isn't something organisations are still waiting on; it's already embedded in enterprise operations. Language models handle customer support tickets. Recommendation engines surface products to millions of users. Fraud detection systems make real-time decisions that affect people's lives.
Behind every one of these deployments is an attack surface that most security teams have never been trained to assess.
Traditional threat modelling provides a strong foundation, and frameworks like have helped defenders systematically identify security threats for over two decades. But systems introduce assets, behaviours, and failure modes that those frameworks weren't designed to handle. can be poisoned. Model weights can be stolen. Prompts can be injected. And the outputs? They're non-deterministic, meaning the same system can behave differently each time it's queried.
If your organisation is deploying (and chances are it is), your threat models need to evolve.
Learning Objectives
- Identify -specific assets and attack surfaces that don't exist in traditional applications
- Apply threat categories to / system components with appropriate context
- Use to enumerate adversarial techniques targeting systems
- Map Top 10 risks to architectural components to identify where threats live and how to prioritise them
- Produce a structured threat assessment for an deployment
Prerequisites
- A basic understanding of Threat Modelling concepts (familiarity with is helpful, but we'll do a refresher)
- Knowledge of Web Application Security and Security Principles
- A foundational understanding of / Security Threats concepts
This room is defender-focused, you'll learn to evaluate and document threats, not exploit them.
The Scenario
You've recently joined MegaCorp's security team as a threat analyst. The company has aggressively adopted across multiple business functions:
- A customer-facing chatbot powered by a large language model, connected to internal knowledge bases through a retrieval-augmented generation () pipeline
- An internal recommendation engine processing sensitive customer data to personalize product offerings
- An automated fraud detection system making real-time authorization decisions on financial transactions
Your CISO has tasked you with conducting a threat assessment of these deployments. Executive leadership is concerned about recent headlines, including systems being manipulated, being extracted, and models behaving unpredictably, and they want to understand MegaCorp's risk exposure before the quarterly board meeting.
You have one week to deliver a comprehensive threat model. Let's get to work.
I understand the learning objectives and am ready to learn about AI threat modelling!
If you have threat modelled traditional applications before, you are used to thinking about a familiar set of assets: databases, source code, configuration files, keys, and user credentials. You know what they are, where they live, and how to protect them.
systems change the picture. They introduce an entirely new class of assets that most security teams have never had to inventory, classify, or defend. Missing these assets during a threat assessment means missing entire categories of risk, and that's exactly the gap attackers exploit.
Let's map out what's new.
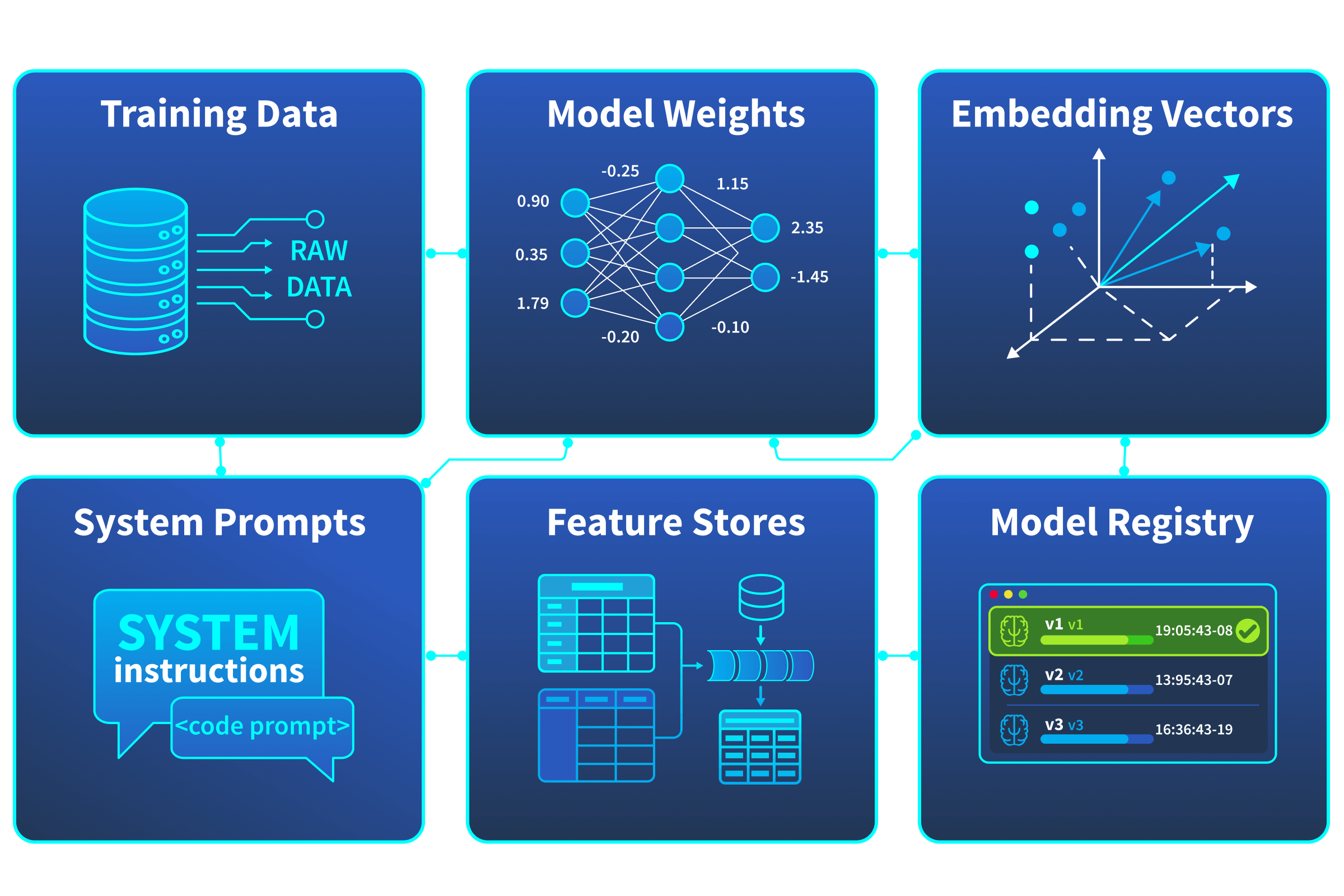
Assets You Need to Know
| Asset | What It Is | Why It Matters |
|---|---|---|
| The datasets used to teach the model its behaviour | Poisoning this data corrupts the model's outputs at the source. Unlike a database compromise, the damage is baked into the model itself. | |
| Model Weights / Parameters | The numerical values that define what the model has learned | These are the model. Stealing them means an attacker has a functional copy of your , months of compute and potentially millions in investment, gone. |
| Vectors | Numerical representations of text or data used for similarity computation, retrieval, or as input features to downstream models | Used in , recommendation engines, and fraud detection systems. Poisoning or manipulating embeddings alters what information models see at query time. |
| System Prompts | Instructions that define the model's behaviour, constraints, and persona | Leaking these reveals your security controls, business logic, and guardrails, giving attackers a roadmap to bypass them. |
| Feature Stores | Preprocessed data repositories that feed real-time model inputs | Tampering with features changes what the model "sees" at inference time, without touching the model itself. |
| / Artifacts | Stored versions of trained models ready for deployment | A compromised registry means an attacker can swap a legitimate model for a backdoored one, and no one may notice until it's too late. |
None of these assets map neatly onto traditional asset categories. A stolen database is serious, but a stolen model is a fundamentally different kind of loss, you can't just rotate a credential and move on. The asset that defines the model's learned behaviour is its model weights; once those are exfiltrated, the attacker has a functional copy of your . Meanwhile, if an attacker wants to give themselves a roadmap of your 's security controls and behavioural constraints, the asset they would target is your system prompts. And a poisoned set doesn't trigger the same alerts as a modified database record, because the corruption only surfaces after the model has been retrained and redeployed.
What Else Makes Systems Different
Beyond new asset types, systems also behave differently from traditional software, affecting how we model threats. Two characteristics worth noting:
- Non-deterministic behaviour: models, especially LLMs, can produce different outputs for the same input. This makes testing, auditing, and incident reproduction significantly harder than with deterministic software. If you've completed earlier rooms in this path, you'll already be familiar with this concept.
- The black box problem: Most models, particularly deep neural networks, lack the explainability of traditional application logic. You can't step through a model's reasoning the way you'd trace a code path. This forces defenders to think in terms of input-output behaviour and failure modes rather than code-level inspection.
Both of these characteristics have direct implications for threat modelling, and we will see them repeatedly surface as we work through the frameworks in upcoming tasks. For now, the key takeaway is simple: systems aren't just traditional applications with a model bolted on. They have different assets, behaviours, and ways of failing, and our threat models need to account for all of it.
In a RAG-based system, which AI asset type is used to retrieve relevant context at query time?
An attacker gains access to MegaCorp's model registry and swaps the production model for a modified version. Which AI-specific asset has been compromised?
In the previous task, we mapped out the new assets that systems introduce. But knowing what to protect is only half the picture. We also need to understand how those assets are built, moved, and consumed, because every step in that process is an opportunity for compromise.
This is where the data supply chain comes in.
The Data Supply Chain
Traditional applications have software supply chains, dependencies, libraries, images. You have likely already encountered supply chain threats in the form of compromised packages or malicious dependencies. systems inherit all of those risks and add an entirely separate supply chain built around data.
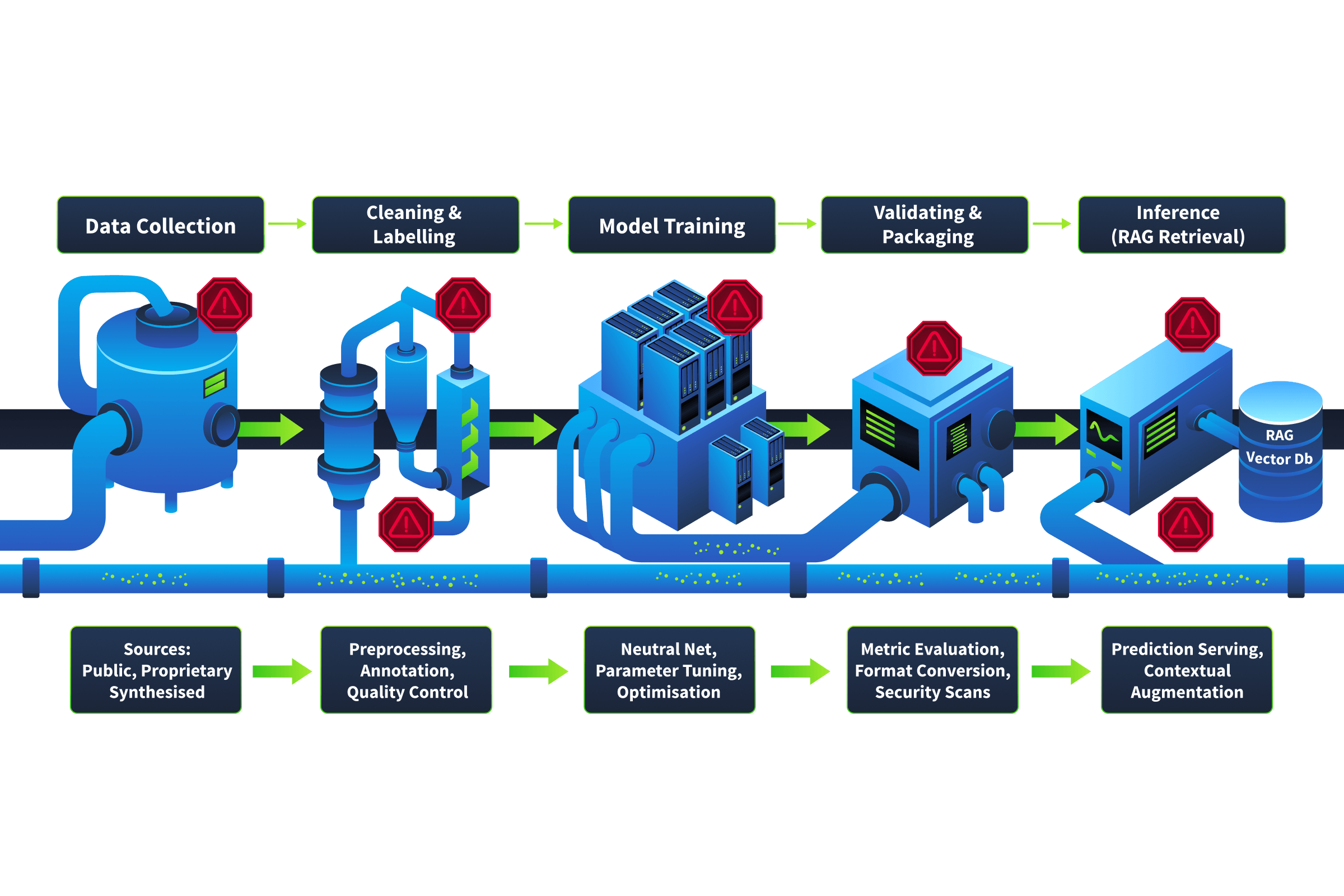
Here's how a typical model goes from raw data to production:
Stage 1: Data Collection
is gathered from multiple sources, including web scraping, purchased datasets, internal databases, user-generated content, and third-party providers. At this stage, an attacker who can contribute or influence any of these sources has a foothold.
Stage 2: Cleaning and Labelling
Raw data is preprocessed, filtered, and labelled. In some this involves external annotation teams or automated labelling tools. In other cases, such as fraud detection, labels are derived implicitly from outcomes, like chargebacks or investigation results. Regardless of the method, compromised labels lead the model to learn the wrong associations. A mislabelled dataset doesn't look corrupted. It just quietly teaches the model to make incorrect decisions.
Stage 3: Model Training
The model learns patterns from the prepared data over days or weeks of compute. Any poison that survived the first two stages is now embedded in the model's weights. Unlike a compromised library you can patch, a poisoned model may need to be retrained from scratch, at significant time and cost.
Stage 4: Validation and Packaging
The trained model is evaluated, versioned, and stored in a for deployment. If the registry itself is compromised, an attacker can swap a validated model for a backdoored one. The backdoored model passes standard validation checks because the trigger inputs (the specific patterns that activate the malicious behaviour) are absent from the validation dataset. Everything looks clean until the model encounters those triggers in production.
Stage 5: Inference
The model serves predictions in production. For -based systems, this stage often includes a retrieval pipeline that retrieves additional context from vector databases or document stores at query time, introducing yet another injection point that doesn't exist in traditional applications.
Each stage is a link in the chain, and each link is a potential point of compromise. The critical difference from traditional software supply chains is time. A compromised npm package can be detected and reverted within hours. A poisoned training dataset may not reveal its effects for weeks or months, only surfacing after the model is retrained, validated, and deployed to production.
Think about it for MegaCorp: The fraud detection system is retrained monthly on new transaction data. If an attacker can inject crafted transactions into that training pipeline over several months, they can gradually shift the model's decision boundaries, making specific fraud patterns invisible to detection. By the time anyone notices, the model has been approving fraudulent transactions for weeks.
Why Alone Falls Short
Now that we understand 's new assets and new supply chain concept, let's address the framework question: can we just use as-is?
(Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, Elevation of Privilege), has been the backbone of threat modeling since Microsoft introduced it in the late 1990s. It remains highly effective for traditional applications. But when applied to systems without adaptation, it has documented gaps:
Data isn't a first-class concern at the training level. 's Tampering category works well for data in transit or at . But tampering with is fundamentally different, the effects are diffuse, delayed, and nearly invisible. A poisoned training set doesn't throw an error. It produces a model that behaves incorrectly in subtle, hard-to-detect ways.
Adversarial manipulation of model behaviour doesn't fit neatly into one category. Crafting inputs designed to make a model misclassify, hallucinate, or bypass safety guardrails spans multiple categories simultaneously, it's part Tampering, part Spoofing, part Elevation of Privilege depending on context. wasn't designed for threats that blur across categories this way.
The scope of privilege has expanded beyond what originally envisioned. When a model can take actions, browse the web, execute code, send emails, query databases, the Elevation of Privilege category still applies, but what constitutes "privilege" is fundamentally broader. A jailbroken chatbot with tool access isn't just a traditional privilege escalation. The model's entire set of tool permissions becomes the attacker's capabilities.
Model-specific intellectual property theft is a different kind of disclosure. Extracting a model's weights through carefully crafted queries is technically Information Disclosure, but it's profoundly different from exfiltrating a database. The stolen asset is the organisation's entire capability, not a dataset, but a trained intelligence.
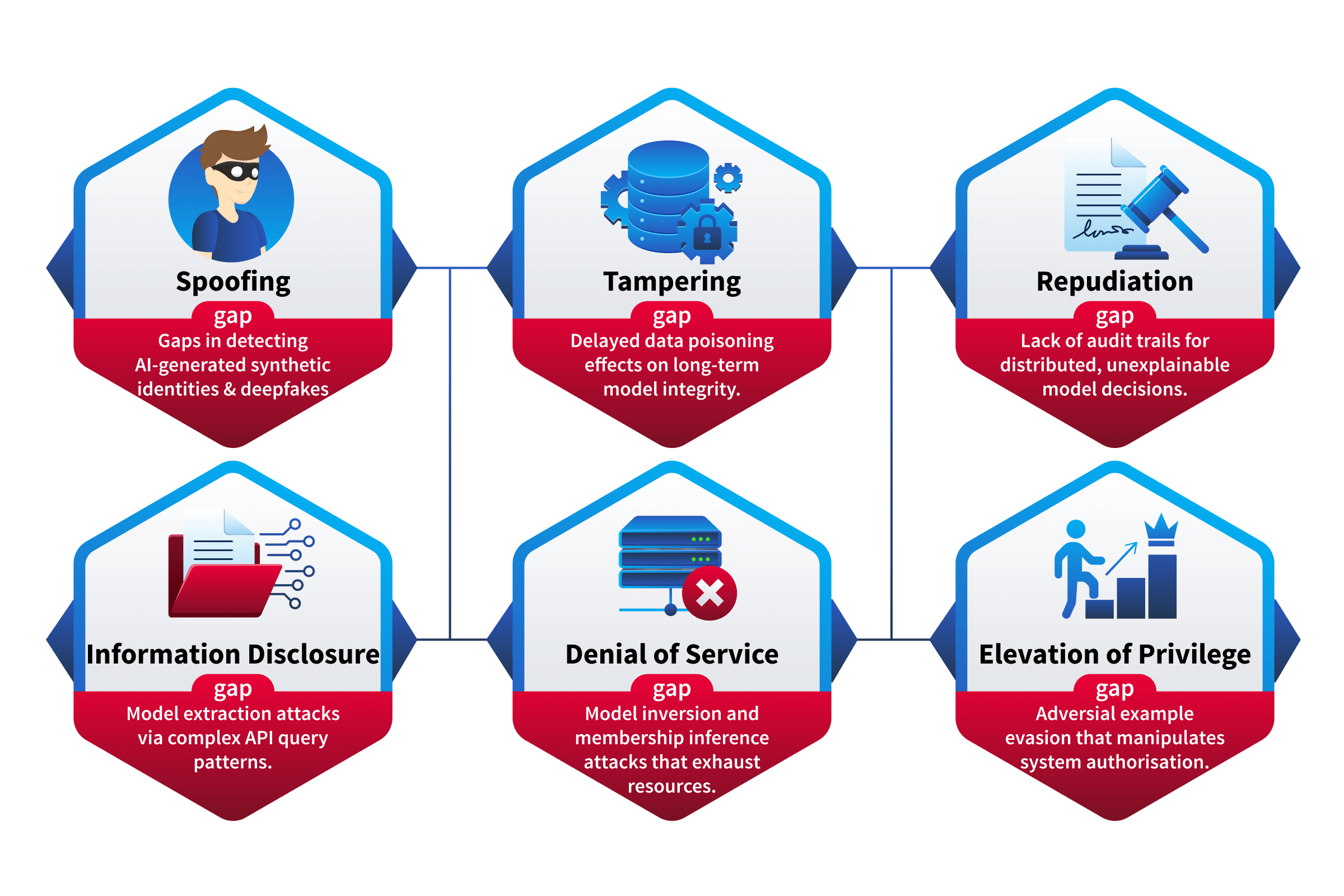
This isn't a criticism of , it's a recognition that the framework needs adaptation, not replacement. The six categories are still valuable lenses for threat identification. They just need to be retuned for the context.
In the next task, we will walk through each category and map it to its -specific manifestations, using MegaCorp's architecture as our working example. We will also introduce technique so you can start building a shared vocabulary for threats that goes beyond 's six categories.
An attacker injects crafted data points into a training pipeline over several months, gradually shifting the model's decision boundaries. At which supply chain stage does the attacker inject the malicious data?
Which STRIDE category is insufficient for capturing the delayed, diffuse effects of training data poisoning?
We don't need to throw away, we need to retool it. is already familiar to most security professionals, and that familiarity is an advantage. Rather than learning an entirely new framework from scratch, we can adapt what we already know. The key is understanding how each category manifests differently when applied to components.
Refresher

| Threat Category | Security Property Violated | Traditional Meaning |
|---|---|---|
| S — Spoofing | Authenticity | Pretending to be someone or something you're not |
| T — Tampering | Modifying data or code without authorisation | |
| R — Repudiation | Non-repudiability | Denying that you performed an action |
| I — Information Disclosure | Confidentiality | Exposing information to unauthorised parties |
| D — Denial of Service | Availability | Making a system or resource unavailable |
| E — Elevation of Privilege | Authorisation | Gaining access or capabilities beyond what's permitted |
In traditional threat modelling, you decompose a system into components, then walk through each component in these six categories. We'll do the same for systems, but the answers look very different.
1. S — Spoofing: Data Source Impersonation
Traditional: An attacker forges credentials to impersonate a legitimate user or service.
Primary Manifestation → Data Source Impersonation. In architectures, the model retrieves context from external sources, vector databases, document stores, and web content and treats that context as trustworthy. An attacker who can inject content into these sources effectively spoofs the knowledge the model relies on, causing it to generate responses grounded in attacker-controlled information.
Other -related spoofing threats include:
- Model impersonation: deploying a look-alike endpoint that mimics a legitimate service
- Adversarial identity attacks: crafting inputs that fool -based identity verification systems (facial recognition, voice auth)
At MegaCorp: The customer-facing chatbot retrieves answers from an internal knowledge base via RAG. If an attacker injects fabricated policy documents into that knowledge base, the chatbot starts confidently serving incorrect information to customers, and neither the chatbot nor the customer knows the source has been spoofed.
2. T — Tampering: Data Poisoning
Traditional: An attacker modifies data in transit or at rest, altering database records, intercepting API responses, changing configuration files.
Primary AI Manifestation → Data Poisoning. An attacker injects malicious data into the training pipeline, causing the model to learn incorrect patterns. Unlike traditional tampering, the effects are delayed, they're embedded during training and only surface during inference. Poisoning can be targeted (forcing specific misclassifications) or untargeted (degrading overall performance).
Other AI-related tampering threats include:
- Model manipulation: directly modifying model weights in storage or swapping models in the registry with backdoored versions
- Prompt injection: manipulating instructions or context the model receives at inference time (direct or indirect). Note that prompt injection's STRIDE classification is context-dependent: it maps to Tampering when the attacker is altering the model's input, but can also manifest as Elevation of Privilege when the goal is bypassing guardrails
- Feature manipulation: altering input features so the model makes decisions based on tampered data
At MegaCorp: The fraud detection system re-trains monthly on new transaction data. An attacker submits crafted transactions over several billing cycles, gradually shifting the model's decision boundaries. Eventually, a specific pattern of fraudulent transactions stops being flagged entirely.
MITRE ATLAS: Data Poisoning — AML.T0020 || Backdoor ML Model — AML.T0018
3. R — Repudiation: Unexplainable Model Decisions
Traditional: A user performs an action and later denies it because the system lacks adequate logging or audit trails.
Primary AI Manifestation → Lack of Decision Audit Trails. When an AI model makes a consequential decision, approves a loan, flags a transaction, or denies a claim, can you trace why? Most models lack built-in explainability. Without robust logging of inputs, outputs, model versions, and retrieval context, reproducing or explaining a specific decision after the fact is extremely difficult.
Other AI-related repudiation threats include:
- Prompt and context volatility: the full context behind an LLM output (system prompt, user input, RAG context, conversation history, temperature) is rarely captured completely
- Model version ambiguity: without deployment logs, you can't attribute a specific output to a specific model state
At MegaCorp: A regulator asks why the fraud detection system approved a suspicious transaction three weeks ago. The security team can't determine which model version was running, what features were fed to it, or what threshold triggered the approval. They have the decision, but not the reasoning.
4. I — Information Disclosure: Model Extraction
Traditional: Sensitive data is exposed through data breaches, insecure APIs, verbose error messages, or improper access controls.
Primary Manifestation → Model Extraction (Model Stealing). An attacker systematically queries a model's API and uses the input-output pairs to reconstruct a functionally equivalent copy of the model. This requires no access to the model's internals; only its public-facing endpoint is needed. The stolen model represents significant intellectual property loss and can be probed offline for adversarial weaknesses.
Other -related information disclosure threats include:
- Training data extraction: crafting queries that cause the model to regurgitate memorised training data, potentially including PII or proprietary content
- System prompt leakage: using prompt extraction techniques to reveal internal instructions, guardrails, and business logic
- Embedding inversion: reversing embedding vectors to reconstruct the original source documents from a vector database
At MegaCorp: A competitor systematically queries the recommendation engine's API with thousands of product-user combinations, collecting the confidence scores returned with each response. Over time, they reconstruct a shadow model that replicates MegaCorp's proprietary recommendation logic, without ever accessing the model weights.
MITRE ATLAS: Extract ML Model — AML.T0024 || Infer Training Data Membership — AML.T0025
5. D — Denial of Service: Inference Cost Exploitation
Traditional: Flooding a system with traffic to exhaust resources and make the service unavailable.
Primary AI Manifestation → Inference Cost Exploitation (Denial of Wallet). AI inference is orders of magnitude more expensive than traditional API calls. In cloud-based deployments billed per token or per query, an attacker can inflict financial damage without taking the system offline. By generating large volumes of expensive queries, long prompts, requests for maximum-length outputs, they drive operational costs to unsustainable levels.
Other AI-related denial of service threats include:
- GPU resource exhaustion: high-volume or complex queries that saturate compute capacity, queuing or dropping legitimate requests
- Sponge examples: adversarial inputs crafted to maximise the computational resources consumed during a single inference call
- Training pipeline disruption: injecting massive volumes of junk data to delay or corrupt retraining cycles
At MegaCorp: A competitor floods the customer chatbot's API with thousands of crafted prompts, each designed to trigger maximum-length responses. The chatbot never goes down, the status page stays green, but the monthly cloud inference bill spikes from $15,000 to $180,000. The system is technically available, but the attack is draining MegaCorp's operational budget.
OWASP LLM Top 10: LLM10:2025 — Unbounded Consumption
6. E — Elevation of Privilege: Jailbreaking and Excessive Agency
Traditional: Gaining higher-level access or capabilities than intended, an unprivileged user getting admin access, a service account performing unauthorised actions.
Primary AI Manifestation → Jailbreaking / Guardrail Bypass. An attacker crafts prompts that cause an to ignore its safety guidelines, content policies, or behavioural restrictions. The model is designed to refuse certain requests, but the attacker's input "elevates" their access to capabilities the model was instructed to restrict. This is conceptually similar to privilege escalation, the attacker doesn't get root on a server, but they gain unrestricted access to the model's full capabilities.
Other AI-related elevation of privilege threats include:
- Excessive agency: when an AI system's tool permissions exceed what's appropriate for its context, turning a chatbot compromise into access to internal databases, email systems, or code execution
- Tool use exploitation: manipulating an agentic AI into using its tools (web browsing, file writing, API calls) for unintended purposes
- Cross-plugin escalation: compromising one plugin's input to affect the model's behaviour with other, more privileged plugins
At MegaCorp: An attacker jailbreaks the customer chatbot, bypassing its content restrictions. The chatbot was also configured with database query tools for looking up order status, but those tools weren't scoped tightly. Through the jailbroken chatbot, the attacker crafts natural language requests that the model translates into database queries against the customer PII table, extracting personal information at scale.
OWASP LLM Top 10: LLM06:2025 — Excessive Agency
What Still Misses
Even with these adaptations, some threats don't map cleanly to any single category:
Adversarial examples: inputs designed to cause misclassification, Tampering, Spoofing, and Elevation of Privilege depending on context. There's no single lens that captures them fully.
Model bias and fairness issues are security-adjacent concerns with real regulatory and compliance implications, but they don't fit traditional threat categories. A biased model isn't being "attacked", it's failing in a way wasn't designed to describe.
Emergent behaviours in large models, capabilities or behaviours that weren't explicitly trained for and may not be anticipated, are a class of risk with no traditional parallel. You can't threat model behaviour that nobody predicted would exist.
These gaps are exactly why we need supplementary frameworks. In the next task, we'll introduce , which provides the comprehensive, -specific technique catalogue that fills these holes and gives defenders a vocabulary that goes beyond 's six categories.
- Consolidated Mapping
| Category | Primary Manifestation | Other Threats | MegaCorp Example |
|---|---|---|---|
| Spoofing | Data source impersonation ( injection) | Model impersonation, adversarial identity attacks | Fake policy docs injected into chatbot knowledge base |
| Tampering | Model manipulation, prompt injection, feature tampering | Crafted transactions shift fraud model's decision boundaries | |
| Repudiation | Lack of decision audit trails | Context volatility, model version ambiguity | Can't explain why fraud model approved a suspicious transaction |
| Info Disclosure | Model extraction / stealing | extraction, prompt leakage, inversion | Competitor reconstructs recommendation engine via queries |
| Denial of Service | Inference cost exploitation (denial of wallet) | GPU exhaustion, sponge examples, pipeline disruption | Chatbot flooded with expensive prompts; bill ($) spikes 12x |
| Elevation of Privilege | Jailbreaking / guardrail bypass | Excessive agency, tool exploitation, cross-plugin escalation | Jailbroken chatbot used to query customer via database tools |
What is the primary AI-specific manifestation of Information Disclosure in the STRIDE-AI mapping?
An attacker crafts prompts that cause an LLM to bypass its safety guidelines and content restrictions. Which STRIDE category does this map to?
Which OWASP LLM Top 10 (2025) entry addresses the risks of AI systems being granted too many permissions or too much autonomy?
An attacker drives your monthly inference bill from $15,000 to $180,000 without taking your service offline. What is this type of attack commonly called?
In the previous task, we adapted for systems, but we also identified gaps where 's six categories don't fully capture -specific threats. This is where (opens in new tab) comes in.
What Is ?
(Adversarial Threat Landscape for Artificial-Intelligence Systems) is a knowledge base of adversary tactics and techniques targeting and systems. Think of it as ATT&CK's -focused counterpart. If you've used ATT&CK (opens in new tab) to map adversary behaviour against traditional infrastructure, gives you the same structured approach for systems.
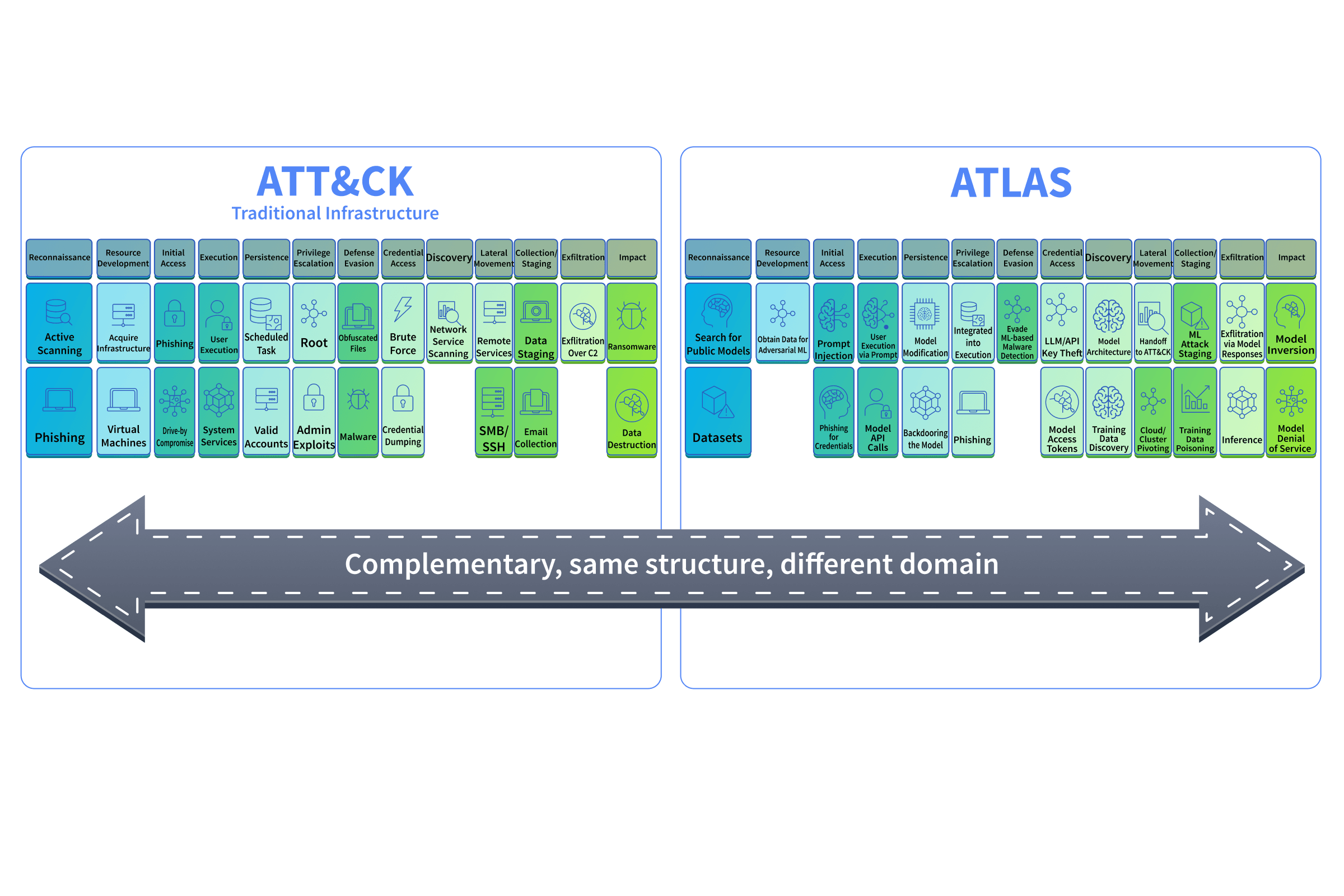
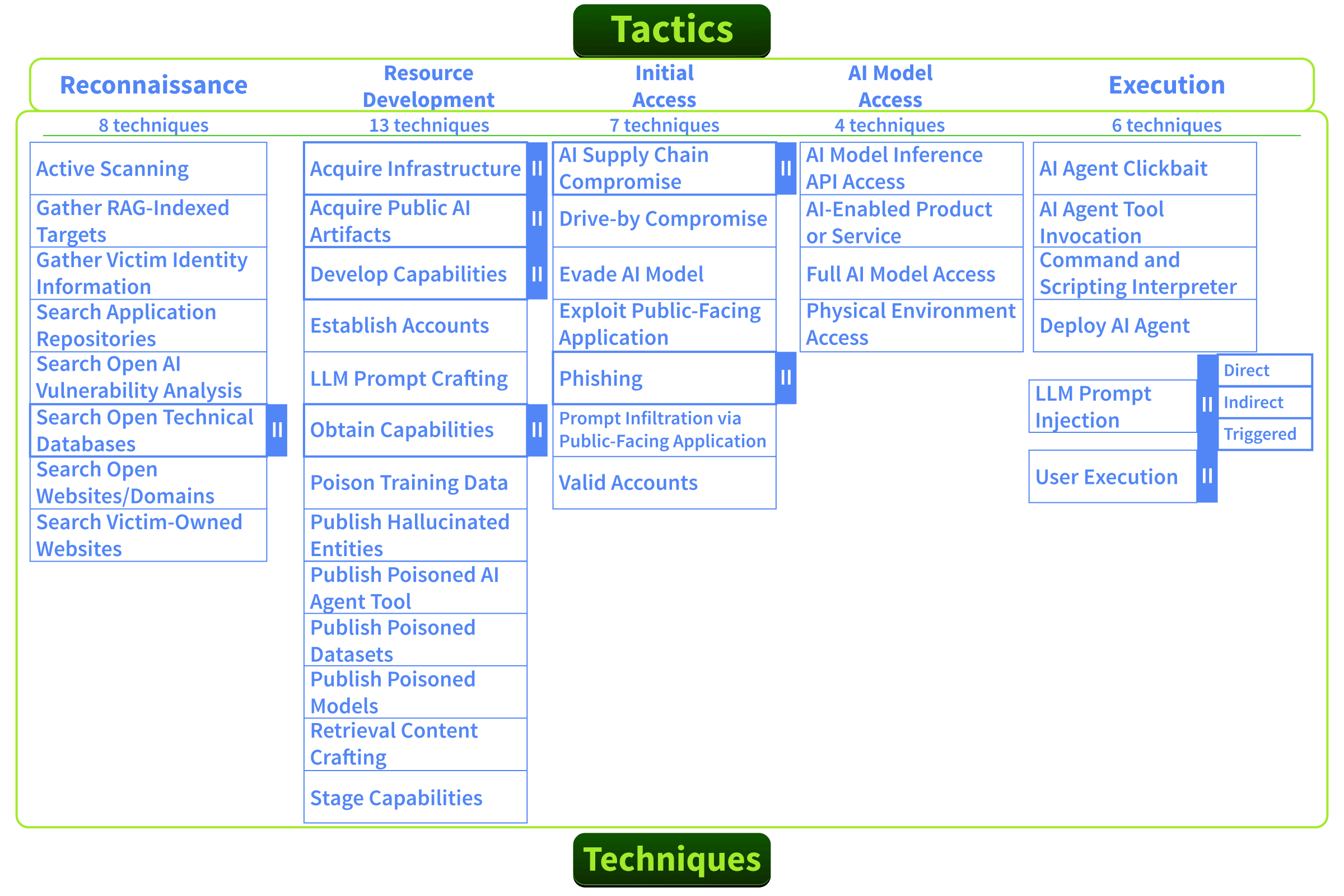
As of the design of this room (early 2026), contains 16 tactics, 155 techniques, 35 mitigations, and 52 real-world case studies. These numbers grow with each update, always check ..org (opens in new tab) for the latest counts. maintains it with contributions from industry, academia, and government.
How Is Structured
follows the same hierarchy you already know from ATT&CK:
| Component | What It Answers | Example |
|---|---|---|
| Tactic | Why the adversary's goal | Attack Staging (AML.TA0012) |
| Technique | How the method used to achieve it | (AML.T0020) |
| Sub-technique | Specifically how a variant of the method | Craft Adversarial Data (AML.T0043.004) |
| Mitigation | What stops it the defensive countermeasure | Input validation, data provenance tracking |
Tactics are the columns of the matrix. Techniques sit within those columns. When you are threat modeling, you start with a tactic (what the attacker wants to achieve) and drill into techniques (how they'd achieve it against your specific system).
Key Techniques You Need to Know
Here are five techniques that are most relevant to the deployments you'll encounter as a defender. Each one maps back to the adaptations we covered in the previous task.
(AML.T0020): Injecting malicious data into training to corrupt model behaviour. Effects are delayed and persist until the model is retrained on clean data. Maps to : Tampering
Model Extraction (AML.T0024): Systematically querying a model's to reconstruct a functional copy. Requires no internal access, just the public endpoint and enough queries. Maps to : Information Disclosure.
Evade Model (AML.T0015): Crafting adversarial data that prevents a model from correctly identifying the contents of the input. This threat spans multiple categories simultaneously, Tampering, Spoofing, and Elevation of Privilege, depending on context. Adversaries may use this to evade malware detection, bypass content filters, or cause misclassification in downstream tasks.
Prompt Injection (AML.T0051): Manipulating an 's behaviour by injecting instructions through direct user input or indirect content the model processes. The distinction matters: direct injection is a user crafting malicious input in the chat interface, while indirect injection is malicious instructions embedded in content the model retrieves or processes (such as documents in a pipeline). For MegaCorp, indirect injection via the knowledge base is the primary vector. Maps to : Tampering
Backdoor Model (AML.T0018): hidden triggers in a model during training. The model performs normally on standard inputs but behaves maliciously when a specific trigger pattern is present. Think of it as a logic bomb, but inside a neural network.
Using During Threat Modeling
isn't a replacement for , it's the enrichment layer. Here's how the two work together in practice:
- Start with : Walk each component through the six threat categories to identify "what could go wrong"
- Enrich with : For each identified threat, look up the corresponding technique to get the specific how, including documented attack methods and real-world case studies
- Apply mitigations: provides recommended countermeasures for each technique, giving you actionable defensive guidance
This two-layer workflow gives you threat categories () and technical detail (). In the next task, we'll add a third layer, Top 10, which maps these risks directly to architectural components and tells you where each threat lives in your deployment.
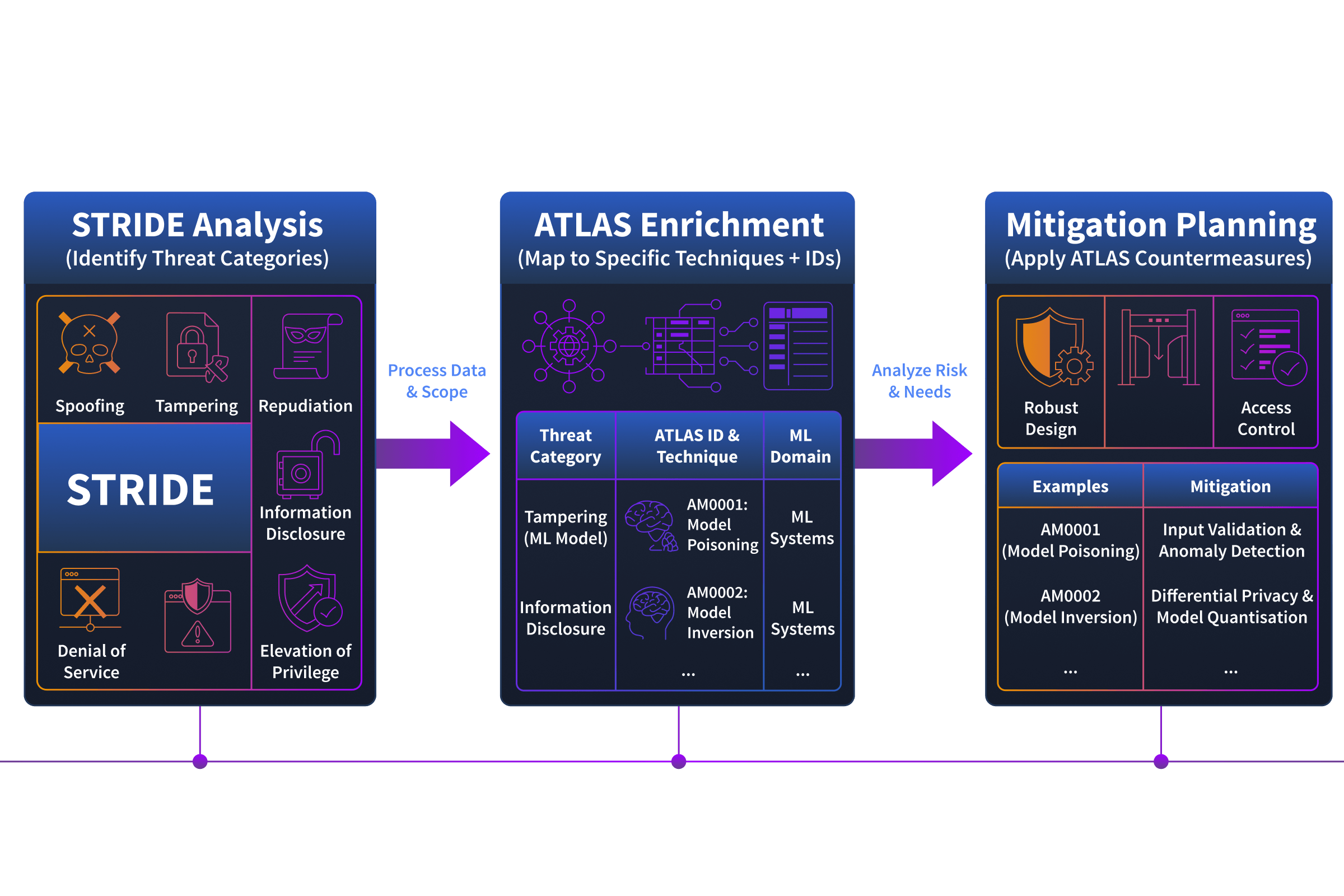
At MegaCorp: During your STRIDE analysis, you identified that the fraud detection system is vulnerable to Tampering via its training pipeline. You open ATLAS and look up Data Poisoning (AML.T0020). The technique page tells you: this can be targeted or untargeted, the attacker needs access to the training data source, and recommended mitigations include data provenance tracking, anomaly detection on training inputs, and model performance monitoring for drift. Your threat assessment just went from "tampering risk exists" to a specific, actionable finding with a documented technique ID and defensive playbook.
Real-World Case Studies
includes 52 documented case studies (opens in new tab) of real attacks. Two worth noting:
ShadowRay (opens in new tab) (AML.CS0023): Attackers exploited vulnerabilities in Ray, a popular framework for distributed workloads, to compromise training infrastructure in the wild. This demonstrated that supply chain attacks aren't theoretical, they're happening against production systems.
Morris II Worm (opens in new tab) (AML.CS0024): Researchers demonstrated a self-replicating prompt injection worm that could spread between agents through -based email systems. The worm injected its payload into the model's context without user interaction, extracted , and automatically propagated it to other agents.
Both cases are documented in with full technique mappings, giving you a concrete reference for what these attacks look like in practice.
What does the acronym ATLAS stand for?
Which ATLAS case study described a self-replicating prompt injection worm that spread between AI agents via RAG email systems?
What is the ATLAS technique ID for Model Extraction?
You've adapted for systems and enriched your findings with techniques. Now we introduce the framework that ties it all together for deployments specifically: the Top 10 for Applications (2025).
This isn't just a checklist you run at the end. It's the framework that lets you look at an architecture diagram and immediately say: "This component is exposed to prompt injection. That component is the one that needs hardening against supply chain risk." That's the skill we're building in this task.
What Is the Top 10?
The Top 10 for Applications is a community-driven list of the most critical security risks specific to large language model deployments. Published by the GenAI Security Project, it's built from real-world incidents, researcher findings, and industry consensus.
If you're familiar with the traditional Top 10 (opens in new tab) for web applications, this follows the same philosophy, but focused entirely on -specific risks.
The 2025 List With Component Mapping
The table below doesn't just list the ten risks; it also shows where each risk lives in a typical architecture. This is what turns the Top 10 from a reference document into an actionable assessment tool.
| # | Risk | What It Means | Where It Lives (Vulnerable Components) |
|---|---|---|---|
| LLM01 | Prompt Injection | Attacker manipulates model behaviour through crafted inputs, direct or indirect | inference endpoint (direct injection via user input), vector database / pipeline (indirect injection via retrieved content), any component that feeds text to the model |
| LLM02 | Sensitive Information Disclosure | Model outputs reveal , credentials, or proprietary data | inference endpoint (model memorisation), training pipeline (sensitive data in training set), system prompt (credentials or logic embedded in prompt) |
| LLM03 | Supply Chain | Compromised models, , plugins, or dependencies | Training pipeline (third-party datasets, compromised base models, poisoned fine-tuning data), (models retrieved from external repos such as Hugging Face), plugin/tool integrations (vulnerable or compromised third-party dependencies) |
| LLM04 | Data and | Corrupted or model weights alter behaviour | Training pipeline (data injection point), (model swap), feature store (manipulated input features) |
| LLM05 | Improper Output Handling | outputs aren't validated before downstream use | Web frontend (unsanitised output rendered in browser, risk), gateway (model output passed to downstream services without validation), any system consuming model responses |
| LLM06 | Excessive Agency | granted too many permissions, tools, or autonomy | inference endpoint (where jailbreaking enables tool abuse), tool integrations (database query tools, code execution, email sending), gateway (overly broad permissions granted to the model), agentic orchestration layer |
| LLM07 | System Prompt Leakage | Internal prompts containing sensitive logic or credentials are exposed | inference endpoint (prompt extraction attacks), system prompt configuration (credentials or keys stored in prompts rather than secure vaults) |
| LLM08 | Vector and Weaknesses | Vulnerabilities in systems, vector databases, and embeddings | Vector database ( poisoning, similarity attacks, unauthorised access), pipeline (retrieval manipulation), generation process |
| LLM09 | Misinformation | generates credible-sounding but false content | inference endpoint (hallucination), vector database (stale or incorrect source documents), any user-facing output channel |
| LLM10 | Unbounded Consumption | Uncontrolled resource usage leading to or financial exploitation | inference endpoint (expensive queries, denial of wallet), gateway (insufficient rate limiting), training pipeline (resource-heavy junk data injection) |
Reading the Table Like a Defender
This table is designed to work in two directions:
Risk → Component: "Prompt injection, where does it live?" Look at the row. It primarily targets the inference endpoint and the pipeline. Those are the components that need input validation and prompt boundary enforcement.
Component → Risk: "We're deploying a vector database for , what risks does it carry?" Scan the "Where It Lives" column. The vector database appears under LLM01 (indirect prompt injection), LLM08 ( weaknesses), and LLM09 (misinformation from stale sources). That's your assessment scope for that component.
The second direction is what makes this table powerful in practice. When your organisation adds a new component to an deployment, you can immediately identify which risks it inherits.
Component Risk Profiles
Let's apply this to MegaCorp's architecture. Here are the risk profiles for the three most critical components:
Inference Endpoint carries the highest risk concentration. It appears in seven of the ten entries: LLM01 (prompt injection), LLM02 (sensitive info disclosure), LLM05 (improper output handling), LLM06 (excessive agency), LLM07 (system prompt leakage), LLM09 (misinformation), and LLM10 (unbounded consumption). This is the component that requires the most comprehensive hardening.
Vector Database / Pipeline appears in three entries: LLM01 (indirect prompt injection via retrieved content), LLM08 ( weaknesses), and LLM09 (misinformation from stale or incorrect source documents). Hardening focuses on input validation for indexed content, access controls on the vector store, and freshness monitoring for source documents.
Training Pipeline is the primary component for data and model supply chain threats (LLM03). It appears in three entries: LLM02 (sensitive data entering training), LLM03 (third-party datasets, compromised base models, poisoned fine-tuning data), and LLM04 (data and ). Note that LLM03 also affects plugin or tool integrations via compromised dependencies, but the training pipeline is where third-party models and datasets enter the system through most directly.
Connecting Back to and
, , and aren't competing frameworks, they are layers of the same assessment:
| Layer | What It Does | When You Use It |
|---|---|---|
| - | Categorises threats by type | Initial threat identification, "what could go wrong" |
| Documents specific attack techniques | Enrichment, "how exactly would an attacker do this" | |
| Top 10 | Maps risks to components and prioritises | Assessment and scoping, "where does this risk live and how critical is it" |
Think of it as zoom levels. gives you the wide-angle view. gives you the technical detail. tells you where to point the camera.
How many of the OWASP LLM Top 10 entries affect the LLM Inference Endpoint?
An organisation notices their chatbot is rendering LLM output directly in the browser without sanitisation. Which OWASP entry does this fall under?
Which component in a typical LLM architecture is the primary one that needs hardening against data and model supply chain risks (LLM03)?
Click the green View Site button to open the Threat Modelling exercise: you'll be selecting Top 10 vulnerabilities, mapping them to architecture components, and justifying your choices to put your threat modelling instincts to the test. This task can be used to practice your knowledge of systems and threats. Good luck!
What's the flag?
Over the course of this room, you worked through a complete threat modeling workflow:
- Identified -specific assets , model weights, embeddings, system prompts, feature stores, and model registries, that expand the attack surface beyond traditional applications
- Mapped the data supply chain understanding how data flows from collection through training to inference, and where each stage is vulnerable to compromise
- Adapted for systems, applying the six familiar threat categories with -specific context, from under Tampering to jailbreaking under Elevation of Privilege
- Enriched findings with using the -specific technique catalogue to move from general threat categories to documented attack methods with technique and mitigations
- Mapped risks to components using the Top 10 the primary assessment lens that lets you look at an architecture diagram and immediately identify which components carry which risks and at what severity
- Applied everything to MegaCorp assessing real components, mapping risks with and enrichment, and generating a prioritised threat assessment
The Workflow at a Glance
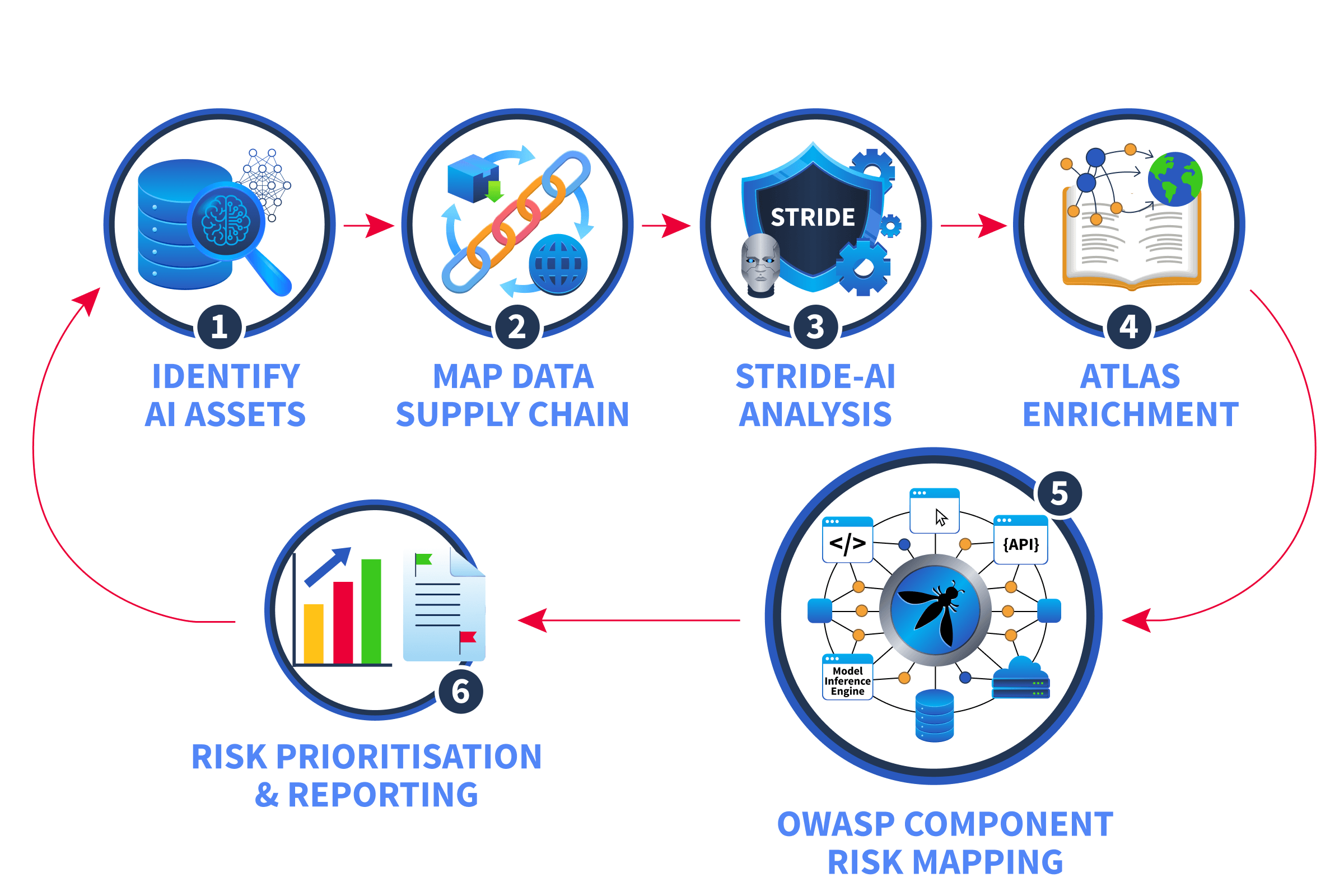
This workflow is repeatable. Every time your organisation deploys a new system, updates a model, or introduces agentic capabilities, you can run the same process. The frameworks evolve, adds new techniques, updates its list, but the methodology stays consistent.
Key Takeaways
systems aren't just traditional applications with a model bolted on. They have different assets, a separate data supply chain, and failure modes that require adapted approaches.
gives you the threat categories, gives you the techniques. Together, they provide the vocabulary; tells you what type of threat you're looking at; tells you exactly how an attacker would execute it and what mitigations to apply.
tells you where to point the camera. The Top 10 is the framework that maps risks directly to architectural components. It's what lets you look at a deployment and say "this component carries these risks at this severity", and that's the skill that makes a threat assessment actionable.
What Comes Next
This room covered the assessment methodology and how to identify and document threats. To go further:
- (opens in new tab): Explore the full technique catalogue, case studies, and mitigations beyond what we covered here
- Exchange (opens in new tab): Explore broader security guidance including agentic and non- systems
I have successfully completed the room!
Ready to learn Cyber Security?
TryHackMe provides free online cyber security training to secure jobs & upskill through a fun, interactive learning environment.
Already have an account? Log in