
Content Discovery
Discover hidden web content using manual techniques, OSINT, and Gobuster enumeration.
easy

To access material, start machines and answer questions login.
In web application security, content refers to anything hosted on a web server, such as pages, files, directories, admin portals, configuration files, and backup archives. Content discovery is the process of finding content that wasn't meant to be publicly accessible or isn't linked anywhere obvious.
This content could be staff portals, older versions of the site, exposed backup files, or administration panels. Finding it is a core part of any web application penetration test.
There are three main approaches to content discovery: manual, automated, and (Open-Source Intelligence). This room covers all three.
Learning Objectives
By the end of this room, you'll be able to:
- Manually discover hidden content using robots.txt, sitemap., favicons, headers, and framework analysis
- Use tools, including Google dorking, Wappalyzer, the Wayback Machine, GitHub, and bucket enumeration
- Use to brute-force directories, subdomains, and virtual hosts
- Apply a structured content discovery methodology in a penetration test
Prerequisites
You should have an understanding of the following rooms before starting:
Machine Access
Set up your virtual environment

I am ready to learn about content discovery!
Several files that web servers expose by convention can reveal far more than intended. Checking these manually should be the first step in any content discovery engagement.
robots.txt
The robots.txt file tells search engine crawlers which pages they may index. Site owners often list sensitive directories here to prevent them from appearing in search results, making it a ready-made list of interesting locations for a penetration tester.
View the robots.txt file on the Acme IT Support website by opening Firefox on the AttackBox and navigating to http://MACHINE_IP/robots.txt (this URL will update 2 minutes after you start the machine).
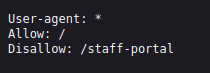
This robots.txt file tells web crawlers (like search engines) how to interact with the site. It allows all bots to access most of the site (Allow: /) but asks them not to visit /staff-portal. Keep in mind, this is only a guideline for bots, not a security control, so restricted paths may still be accessible if visited directly.
sitemap.xml
Unlike robots.txt (which restricts crawlers), sitemap.xml tells search engines which pages the owner wants listed. These files sometimes include staging pages, old content, or URLs that are hard to reach via the normal site. Check it at http://MACHINE_IP/sitemap.xml.
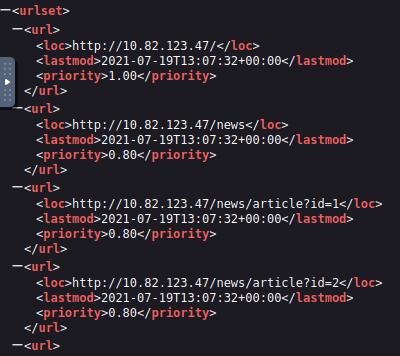
As shown in the image, this sitemap lists specific endpoints available on the target application, including standard pages like /news, /contact, and multiple article IDs (/news/article?id=1,2,3). More importantly, it reveals sensitive or interesting paths such as /customers/login and /s3cr3t-area, which may not be easily discoverable through normal browsing. The presence of parameters like id= also hints at potential input points worth testing. This makes the sitemap a valuable source during reconnaissance for mapping the attack surface.
What is the directory in robots.txt that isn't allowed to be viewed by web crawlers?
What is the path of the secret area found in sitemap.xml?
Headers
When a web server responds to a request, it includes headers that can reveal useful technical details. Headers like Server and X-Powered-By often expose the web server software and the language or framework the application runs on.
Run the following command against the Acme IT Support web server. The -v flag enables verbose output, which includes the response headers:
root@tryhackme:~# curl http://MACHINE_IP -v
* Trying MACHINE_IP:80...
* TCP_NODELAY set
* Connected to MACHINE_IP (MACHINE_IP) port 80 (#0)
> GET / HTTP/1.1
> Host: MACHINE_IP
> User-Agent: curl/7.68.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Server: nginx/1.18.0 (Ubuntu)
< Date: Mon, 04 May 2026 10:39:13 GMT
< Content-Type: text/html; charset=UTF-8
< Transfer-Encoding: chunked
< Connection: keep-alive
< X-FLAG: [REDACTED]
< X-FLAG: [REDACTED]
< X-Powered-By: THM-Framework
<
<!--
This page is temporary while we work on the new homepage @ /new-home-beta
-->
<!DOCTYPE html>
<html lang="en">
<head>
<title>Acme IT Support - Home</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="stylesheet" href="https://pro.fontawesome.com/releases/v5.12.0/css/all.css" integrity="sha384-ekOryaXPbeCpWQNxMwSWVvQ0+1VrStoPJq54shlYhR8HzQgig1v5fas6YgOqLoKz" crossorigin="anonymous">
<link rel="stylesheet" href="/assets/bootstrap.min.css">
<link rel="stylesheet" href="/assets/style.css">
</head>
<body>
<nav class="navbar navbar-inverse navbar-fixed-top">
<div class="container">
<div class="navbar-header">
<button type="button" class="navbar-toggle collapsed" data-toggle="collapse" data-target="#navbar" aria-expanded="false" aria-controls="navbar">
<span class="sr-only">Toggle navigation</span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a class="navbar-brand" href="#">Acme IT Support</a>
</div>
<div id="navbar" class="collapse navbar-collapse">
<ul class="nav navbar-nav">
<li class="active"><a href="/">Home</a></li>
<li><a href="/news">News</a></li>
<li><a href="/contact">Contact</a></li>
<li><a href="/customers">Customers</a></li>
</ul>
</div><!--/.nav-collapse -->
</div>
</nav><div class="container" style="padding-top:60px">
<h1 class="text-center">Acme IT Support</h1>
<div class="row">
<div class="col-md-8 col-md-offset-2 text-center">
<img src="/assets/staff.png">
<p class="welcome-msg">Our dedicated staff are ready <a href="/secret-page">to</a> assist you with your IT problems.</p>
</div>
</div>
</div>
<script src="/assets/jquery.min.js"></script>
<script src="/assets/bootstrap.min.js"></script>
<script src="/assets/site.js"></script>
</body>
</html>
<!--
Page Generated in 0.04765 Seconds using the THM Framework v1.2 ( https://static-labs.tryhackme.cloud/sites/thm-web-framework )
* Connection #0 to host 10.82.123.47 left intact
Look through the response headers carefully; there may be a custom header containing a flag.
Framework Stack
Once you've identified the framework (from the favicon, headers, or by inspecting the page source for comments and copyright notices), visit the framework's own website to learn more. Documentation pages often describe default directory structures, admin panel paths, and default credentials.
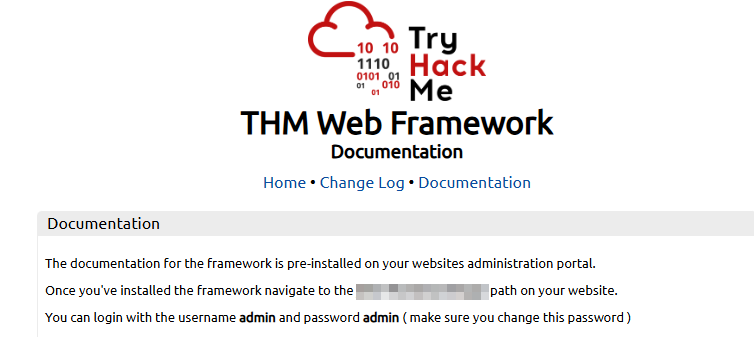
View the Acme IT Support page source at http://MACHINE_IP, there's a comment at the bottom of every page with a link to the framework's website. Follow that link and check the documentation to find the administration portal path. Access that path on the Acme IT Support site and log in with the default admin / admin credentials to retrieve the flag.
What is the flag value from the X-FLAG header?
What is the flag from the framework's administration portal?
There are also external resources available that can help in discovering information about your target website; these resources are often referred to as (Open-Source Intelligence), as they're freely available tools that collect information:
Google Hacking / Dorking
Google's advanced search operators let you filter results in ways that can surface sensitive content indexed from your target. By combining operators, you can find exposed admin panels, leaked documents, and login pages that the site owner never intended to be public.
| Filter | Example | Description |
|---|---|---|
site |
site:tryhackme.com |
Returns results only from the specified domain |
inurl |
inurl:admin |
Returns results with the specified word in the URL |
filetype |
filetype:pdf |
Returns results of a specific file type |
intitle |
intitle:admin |
Returns results with the specified word in the page title |
intext |
intext:password |
Returns results containing the specified word in the body |
cache |
cache:tryhackme.com |
Shows Google's cached version of the page |
For example, site:tryhackme.com filetype:pdf would return all PDFs indexed from tryhackme.com. You can combine multiple filters in a single query. More information is available at Wikipedia: Google Hacking (opens in new tab).
Wappalyzer
Wappalyzer (opens in new tab) is a browser extension and online tool that identifies the technologies a website uses, frameworks, platforms, CDNs, analytics tools, payment processors, and more. It can often detect version numbers, which helps when searching for known vulnerabilities. Install it from your browser's extension store and visit any site to see the tech stack immediately.
What Google dork operator limits results to a specific site?
What online tool and browser extension identifies what technologies a website is running?
Wayback Machine
The Wayback Machine (opens in new tab) is an archive of the Internet dating back to the late 1990s. Search for a domain, and you'll see every snapshot captured over time. This is useful for finding pages that have been removed from the live site but may still be accessible: old login forms, forgotten endpoints, or content that was published briefly before being taken down.
GitHub
(opens in new tab) is a version control system that tracks changes to files over time. GitHub is the most widely used cloud-hosted platform for repositories. Developers sometimes accidentally commit sensitive data: keys, credentials, configuration files, and .env files, before realising the repository is public.
Search GitHub for the company name or domain you're targeting. Once you find a relevant repository, look through the commit history, not just the current files. Sensitive data is often removed in a later commit, but remains in the history.
S3 Buckets
Amazon S3 (opens in new tab) (Simple Storage Service) is a cloud storage platform that many organisations use to host files and static website content. The URL format for an S3 bucket is https://{name}.s3.amazonaws.com. Bucket owners set permissions, but misconfigurations are common: a publicly accessible bucket can expose files that were never meant to be seen.
Common naming patterns include {company}-assets, {company}-backup, {company}-www, and {company}-dev. Try these patterns against your target's company name. You can also find bucket URLs in the website's page source or in GitHub repositories.
What is the website address for the Wayback Machine?
What URL format do Amazon S3 buckets end in? (Answer starts with a .)
Manual and techniques can only take you so far. Automated discovery uses tools to rapidly send hundreds or thousands of requests to a web server to check whether directories, files, or other resources exist. This process relies on wordlists, text files containing commonly used directory names, file names, and paths.
(opens in new tab) is an open-source enumeration tool written in Go. It supports multiple modes: directory/file enumeration (dir), DNS subdomain enumeration (dns), and virtual host enumeration (vhost). It's pre-installed on the AttackBox and included by default in Kali Linux.
Run gobuster --help to see the available commands and global flags:
| Flag | Description |
|---|---|
-t / --threads |
Number of concurrent threads (default: 10). Increase for faster scans. |
-w / --wordlist |
Path to the wordlist file. Required for all modes. |
-o / --output |
Write results to a file instead of stdout. |
--delay |
Wait time between requests: useful against rate-limited servers. |
Wordlists
A good wordlist is critical. SecLists (opens in new tab) is the most widely used collection and is pre-installed on the AttackBox at /usr/share/wordlists/SecLists/. For directory enumeration, Discovery/Web-Content/common.txt and Discovery/Web-Content/directory-list-2.3-medium.txt cover most scenarios.
dir Mode
The dir mode brute-forces directories and files on a web server. The basic syntax is:
The -u flag specifies the target URL that Gobuster will run its discovery against. The -w flag specifies the wordlist file; a list of directory and file names will try against the target one by one. Both -u and -w are required for Gobuster to run; omitting either will result in an error.
Some additional useful flags for dir mode:
| Flag | Description |
|---|---|
-x / --extensions |
File extensions to search for (e.g., -x .php,.txt,.js) |
-r / --followredirect |
Follow HTTP redirects |
-k / --no-tls-validation |
Skip certificate verification (useful in lab environments) |
-s / --status-codes |
Only show specific status codes (e.g., -s 200,301) |
Run the following command against the Acme IT Support web server and review the results:
root@ip-10-82-112-63:~# gobuster dir -u http://MACHINE_IP -w /usr/share/wordlists/SecLists/Discovery/Web-Content/common.txt
===============================================================
Gobuster v3.6
by OJ Reeves (@TheColonial) & Christian Mehlmauer (@firefart)
===============================================================
[+] Url: http://MACHINE_IP
[+] Method: GET
[+] Threads: 10
[+] Wordlist: /usr/share/wordlists/SecLists/Discovery/Web-Content/common.txt
[+] Negative Status codes: 404
[+] User Agent: gobuster/3.6
[+] Timeout: 10s
===============================================================
Starting gobuster in directory enumeration mode
===============================================================
/assets (Status: 301) [Size: 178] [--> http://10.82.123.47/assets/]
/contact (Status: 200) [Size: 3108]
/customers (Status: 302) [Size: 0] [--> /customers/login]
/development.log (Status: 200) [Size: 27]
/monthly (Status: 200) [Size: 28]
/news (Status: 200) [Size: 2538]
/private (Status: 301) [Size: 178] [--> http://10.82.123.47/private/]
/robots.txt (Status: 200) [Size: 46]
/sitemap.xml (Status: 200) [Size: 1383]
Progress: 4655 / 4656 (99.98%)
===============================================================
Finished
===============================================================
As shown in the above output, the scan has discovered several accessible directories and files on the target web application. It reveals common pages like /contact and /news, along with interesting endpoints such as /customers (which redirects to a login page) and /development.log, which may contain sensitive information. Additionally, directories such as /private and /assets were found, along with files such as robots.txt and sitemap., which can further aid reconnaissance. This output helps map the application structure and identify potential entry points for further testing.
What is the name of the directory beginning with /mo that was discovered?
What is the name of the log file that was discovered?
The next mode we’ll focus on is the dns and vhost mode. The dns mode allows Gobuster to brute-force subdomains. During a penetration test, checking the subdomains of your target’s top domain is essential. Just because something is patched in the regular domain, it doesn't mean it is also patched in the subdomain. An opportunity to exploit a vulnerability in one of these subdomains may exist.
For example, if TryHackMe owns tryhackme.thm and mobile.tryhackme.thm, there may be a vulnerability in mobile.tryhackme.thm that is not present in tryhackme.thm. That is why it is important to search for subdomains as well!
Subdomains vs Virtual Hosts
It's important to understand the difference between these two concepts before using Gobuster to enumerate them:
- A subdomain is resolved through DNS. For example,
blog.example.thmis a record that points to an IP address. - A virtual host (vhost) is resolved by the web server. Multiple sites can run on the same IP address, with the server using the
Host:HTTP header to decide which site to serve.
As mentioned, Gobuster has separate modes for each: dns for subdomains and vhost for virtual hosts.
Preparing the Environment
We are going to work in a local network with a DNS server on the web server. To ensure we can resolve the domains used throughout this room, you need to change the /etc/resolv-dnsmasq file:
- Open up a terminal on the AttackBox and enter the command:
sudo nano /etc/resolv-dnsmasq. - Insert
nameserver MACHINE_IPas the first line. - Save the file by pressing
CTRL+O, followed by pressingENTER, and then exit the editor by pressingCTRL+X. - Enter the command
/etc/init.d/dnsmasq restartto restart the Dnsmasq service.
The file should look something like this:
root@tryhackme:~# cat /etc/resolv-dnsmasq
nameserver MACHINE_IP
nameserver 169.254.169.253
Updating the Host File
To ensure the domain used in this room resolves correctly, we need to manually map it to the target IP using the /etc/hosts file:
- Open a terminal on the AttackBox and run:
sudo nano /etc/hosts. - Add the following line at the end of the file:
MACHINE_IP example.thm. - Save the file by pressing
CTRL+O, thenENTER, and exit usingCTRL+X. - You can verify the change by running:
ping example.thm.
The file should look something like this:
root@ip-10-82-108-230:~# cat /etc/hosts
127.0.0.1 localhost
127.0.0.1 vnc.tryhackme.tech
127.0.1.1 tryhackme.lan tryhackme
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
MACHINE_IP example.thm
dns Mode
The dns mode performs lookups using wordlist entries as subdomain candidates. The required flags are -d (domain) and -w (wordlist). The --wildcard option in Gobuster is used to force enumeration even when wildcard DNS is detected, allowing results to be returned despite potential false positives.
In the AttackBox, enter the following command:
root@tryhackme:~# gobuster dns -d example.thm -w /usr/share/wordlists/SecLists/Discovery/DNS/subdomains-top1million-5000.txt --wildcard
===============================================================
Gobuster v3.6
by OJ Reeves (@TheColonial) & Christian Mehlmauer (@firefart)
===============================================================
[+] Domain: example.thm
[+] Threads: 10
[+] Wildcard forced: true
[+] Timeout: 1s
[+] Wordlist: /usr/share/wordlists/SecLists/Discovery/DNS/subdomains-top1million-5000.txt
===============================================================
Starting gobuster in DNS enumeration mode
===============================================================
Found: shop.example.thm
Found: www.shop.example.thm
Found: webdisk.shop.example.thm
Found: autodiscover.shop.example.thm
Found: autoconfig.shop.example.thm
Found: academy.example.thm
Found: primary.example.thm
Progress: 4997 / 4998 (99.98%)
===============================================================
Finished
===============================================================
Some useful flags for dns mode are:
| Flag | Description |
|---|---|
-d / --domain |
The target domain to enumerate |
-i / --show-ips |
Show the IP addresses that subdomains resolve to |
-r / --resolver |
Use a custom DNS server for lookups |
vhost Mode
The vhost mode doesn't use . Instead, it sends HTTP requests to the target IP, cycling through wordlist entries as the Host: header value. This finds virtual hosts that aren't registered in public DNS.
Run the vhost scan with the following commands. The --append-domain flag tells Gobuster to combine each wordlist entry with the domain, and --exclude-length filters out false positives that share a common response size:
root@tryhackme:~# gobuster vhost -u "http://MACHINE_IP" --domain example.thm -w /usr/share/wordlists/SecLists/Discovery/DNS/subdomains-top1million-5000.txt --append-domain --exclude-length 250-320
===============================================================
Gobuster v3.6
by OJ Reeves (@TheColonial) & Christian Mehlmauer (@firefart)
===============================================================
[+] Url: http://10.82.123.47
[+] Method: GET
[+] Threads: 10
[+] Wordlist: /usr/share/wordlists/SecLists/Discovery/DNS/subdomains-top1million-5000.txt
[+] User Agent: gobuster/3.6
[+] Timeout: 10s
[+] Append Domain: true
[+] Exclude Length: 259,271,291,293,306,252,264,304,308,263,301,298,307,309,254,261,267,283,295,318,265,292,320,270,289,313,314,319,268,272,286,312,258,277,287,294,317,251,285,315,302,257,260,262,275,284,266,279,281,297,305,311,250,273,278,282,290,256,276,269,296,310,316,274,300,303,253,255,280,288,299
===============================================================
Starting gobuster in VHOST enumeration mode
===============================================================
Progress: 4997 / 4998 (99.98%)
===============================================================
Finished
===============================================================
Review the results and identify the virtual hosts responding with a 200 OK status. Access each one in your browser to explore what's hosted there.
As shown in the above output, a virtual host enumeration was performed using to identify hidden subdomains associated with the target. The scan used a large wordlist and filtered out common response lengths to reduce noise, focusing only on meaningful results. However, no valid virtual hosts were discovered during the scan, indicating that there are likely no additional subdomains configured for this application. This suggests that further testing should focus on the main domain and the identified directories.
Apart from dns and -w, which shorthand flag is required for dns mode?
How many virtual hosts on acmeitsupport.thm respond with status code 200?
Content discovery is one of the most important phases of web application reconnaissance. The techniques in this room work together: manual checks surface quick wins, finds information the target has already shared publicly, and automated tools cover the breadth that neither approach can do alone.
Here's a quick recap of what was covered:
| Method | Techniques |
|---|---|
| Manual | robots.txt, sitemap., favicon fingerprinting, headers, framework stack |
| Google dorking, Wappalyzer, Wayback Machine, GitHub, buckets | |
| Automated | dir, , and vhost modes |
A good content discovery workflow runs all three methods against a target before moving to exploitation. The directories and files you find here feed directly into later stages of a penetration test.
I have successfully completed the room!
Ready to learn Cyber Security?
TryHackMe provides free online cyber security training to secure jobs & upskill through a fun, interactive learning environment.
Already have an account? Log in