
Hacking Hadoop
Learning about the security failings commonly seen in Hadoop
hard

To access material, start machines and answer questions login.
- you need to wait 10 minutes after the lab has started for the cluster to become fully active.
- you can confirm that the lab is ready by running the scan of your choice to confirm that port 8080 is open on 172.23.0.3.
172.23.0.3- This is your primary target, an edge node in the Hadoop network.172.23.0.4- In Hadoop terms, this is called the "master" node. Your final flag is here and root access signifies full Hadoop compromise.172.23.0.2- This is the simulated server. This server is out of scope for this challenge.
Set up your virtual environment

Welcome to the Hadoop network!
Start by loading this lab.
Once your lab has started, before you can use the from the previous task, you will have to add the machine as a static host. This can be done using the following command:
sudo bash -c "echo 'MACHINE_IP thm_hadoop_network.net' >> /etc/hosts"
Once this is done and you have given the lab some time to boot, you can start your Hadoop network VPN using the following command:
sudo openvpn thmhadoopvpn.ovpn
Verify that your lab is up and running by trying to ping 172.23.0.3 and verify that Hadoop has finished booting by ensuring port 8080 is open on this host.
In this challenge, you will be guided to compromising a datalake. Most large organisations out there have at least one datalake, some even more, and the most widely used datalake technology out there is Hadoop!
This task will give you a brief overview of Hadoop before you jump into your hacking activities.
Hadoop terminology?
There are some key terms used in Hadoop that you should know to make this hacking journey easier. It should be noted that Hadoop still makes use of the terms master and slave, since primary and secondary already have specific meanings in the context of Hadoop.
- Cluster - Refers to all the systems that together make the datalake.
- Node - A single host or computer in the Hadoop cluster.
- NameNode - A node that is responsible for keeping the directory tree of the Hadoop .
- DataNode - A slave node that stores files according to the instructions of a NameNode.
- Primary NameNode - The current active node responsible for keeping the directory structure.
- Secondary NameNode - The backup node which will perform a seamless takeover of the directory structure should the Primary NameNode become unresponsive. There can be more than one Secondary NameNode in a cluster, but only one Primary active at any given time.
- Master Node - Any node that is executing a Hadoop "management" application such as HDFS Manager or YARN Resource Manager.
- Slave Node - Any node that runs a Hadoop "worker" application such as HDFS or MapReduce. It should be noted that a single node can be both a Master and Slave node at the same time.
- Edge Node - Any node that is hosting a Hadoop "user" application such as Zeppelin or Hue. These are applications that users can use to perform processing on the data stored in the datalake.
- Kerberised - The term given for a datalake that has security enabled through .
What is Hadoop?
Hadoop is a datalake technology developed by . It is a collection of open-source applications and services that can utilise a network of computers to solve large and complex problems. Hadoop in its simplest form has two main functions namely distributed storage and distributed processing.
In essence, it allows a network of computers to become one very large computer with a massive hard drive and a ton of power. How big are we talking? Well, let's just put it this way, most organisations have clusters of about 200 nodes each with about 25 TeraBytes of storage equalling a staggering 5 PetaBytes of storage and roughly 1700 CPUs. To ensure network speed is not a bottleneck, usually, these nodes are connected to each other through multiple fibre lines. The world's largest cluster? 2000+ nodes with 21 PB of storage capacity and 22000+ CPUs.
What are the services of Hadoop?
The diagram below shows an example of a Hadoop ecosystem. Note that there are many more services that can be integrated:
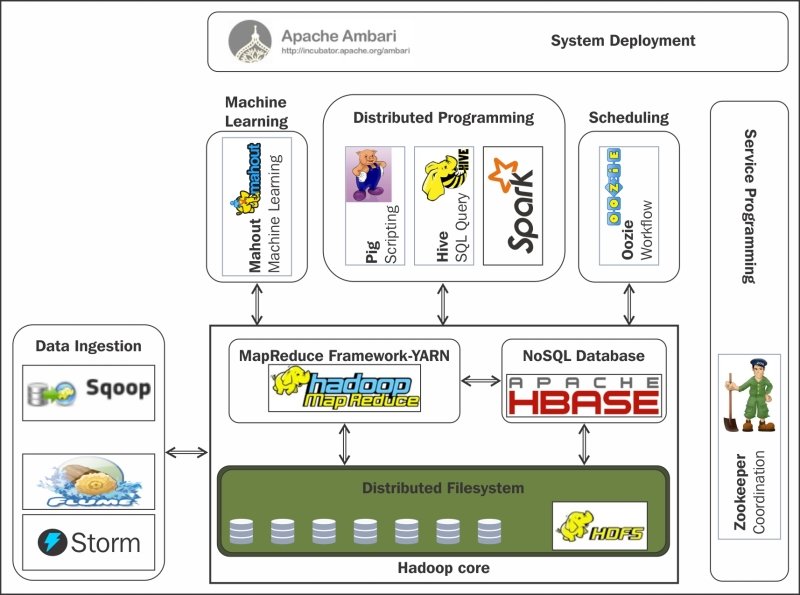
There are quite a number of different Hadoop applications and services. These are some of the most common ones:
- HDFS - Hadoop Distributed is the primary storage application for unstructured data such as files
- Hive - Hive is the primary storage application for structured data. Think of it as a massive database.
- YARN - Main resource manager application of Hadoop, used to schedule jobs in the cluster
- MapReduce - Application executor of Hadoop to process vast amounts of data. It consists of a Map procedure, which performs filtering and sorting, and a reduce method, which performs a summary operation.
- HUE - A user application that provides a for HDFS and Hive.
- Zookeeper - Provides operational services for the cluster to set the configuration of the cluster in question.
- Spark - Engine for large-scale data processing.
- Kafka - A message broker to build for real-time data processing.
- Ranger - Used for the configuration of privilege access control over the resources in the datalake.
- Zeppelin - A web-based notebook application for interactive data analytics.
There are more for you to discover on your own, but the fun part? All of these applications are open source, so you can download the source code and create your very own instance to play around with! In this lab, our focus will be mainly on primary applications such as HDFS and YARN.
Is security even a thing in Hadoop?
Short answer, for a really scary long time, no. But over the years improvements have been made. The two biggest improvements were the introduction of authentication through and PAM through optional applications such as Ranger. Optional is the scary word there. A lot of datalakes out there simply don't make use of these security controls.
In this lab, we will be looking at a Kerberised datalake, so there is some security, but common misconfigurations have led to this datalake being insecure.
Note: We will provide assistance on the Hadoop specific components, but basic enumeration, exploitation, and privilege escalation techniques will be expected for you to complete this lab.
What type of node provides applications for users?
What Hadoop service is responsible for scheduling jobs?
What Hadoop service provides granular access control to resources?
What is the term provided to a datalake that makes use of Kerberos for security?
Who owns the largest Hadoop cluster in the world?
Let's start the fun. Before we can begin to attack, you will have to do some recon. Using your favorite network scanner and its associated flags, enumerate the services exposed by 172.23.0.3.
There are going to be a bunch of different services and ports exposed. However, reviewing some of them you will quickly realise that this Hadoop environment is kerberised. Meaning the only way in is through a legitimate service.
Using a breadth-first approach, try to enumerate these services and find the edge node applications that are available. One of these will be your primary target.
Note: When you finally authenticate, DO NOT rush to , you will shoot yourself in the foot. Take time to first read through the provided loot and maybe save a copy of it.
What file is responsible for the authentication configuration for this service?
What is the username and password combination that gives you your initial entry? (Format: <username>:<password>)
Once authenticated, submit the flag that is hiding nicely in one of the notebooks.
So you found a nice service? Not all roles are created equal.
This is the first misconfiguration you will see in many datalakes that have the initial security applied. Due to the sheer amount of applications and services running in a datalake, you are bound to find at least one service that still makes use of default credentials and configuration.
After exploring the loot here, let's see what we can do to gain access to this edge node.
This application is a very popular Hadoop application. Similar to Jupyter notebooks, it allows data analysts to quickly writeup scripts that can pull, process, and display analytics from the data stored in the cluster. It does this by making use of interpreters, of which there are many to choose from. However, not all interpreters are equal. Similarly, not all user roles are equal.
How does authentication work for this service? Could you perhaps do some lateral privilege escalation to execute code?
You will find the next flag in the home directory of the compromised user.
Which active interpreter can be used to execute code?
What OS user does the application run as?
What is the value of the flag found in the user's home directory (flag2.txt)?
Finally, you have . At this point, you should probably consider getting a stable shell using your preferred method. While the entire challenge can be solved from a single notebook, this is just making your life more difficult than it honestly should be. Go get that stable shell before moving on.
Note: A bit of an added twist, but reverse shells will probably not do the trick in this lab, since the Hadoop network does not have the relevant routes to communicate back on the . This is often normal behaviour in Hadoop networks for additional security, ensuring that the network can't communicate out itself. This may be the ideal time to test your bind shell (opens in new tab) skills.
You're back? Awesome!
You are still left with the same problem, you can't access the datalake without authentication. The question then becomes, if everything has to do with authentication, how can this process be automated? If you have this many Hadoop services running and each of them has to authenticate itself before it can perform actions, there has to be an automated way of doing this? Ever heard of keytabs?
Keytabs are magical things. Think of them as a Key. Essentially, you are storing all the information required (including the password) to authenticate in a file. Keytabs can be generated by interfacing with the server and executing the following command:
ktpass /pass <Krb Password> /mapuser <Krb Username> /out <ex.keytab> /princ <username>/<hostname>@<example.com> /ptype KRB5_NT_PRINCIPAL /crypto RC4-HMAC-NT /Target example.
But wait, how is that secure? Simple! The security of keytabs relies on restricting access to the associated keytab file. So file permissions should be used to protect the keytab file in question, similar to how SSH private keys are protected. However, by default, these keytab files do not inherit secure file permissions, especially during the initialisation phase when the datalake is created and these keys have to be distributed to each node in the cluster.
With this being said, go find the keytabs of the Hadoop services stored on this host. Use whatever enumeration techniques or scripts you would normally follow for privilege escalation after the initial compromise.
Did you find them? Great! Now let's use them.
Let's start small. Let's try to authenticate with Keberos and the keytab associated with our user. The following guide provides excellent assistance on using keytabs for authentication:
https://kb.iu.edu/d/aumh (opens in new tab) (opens in new tab)
We are interested in two commands:
klist:
The klist command can be used to gather information from a keytab, since cat'ing the keytab usually ends badly for your shell. We can use the following command to output the principals stored in the keytab file:
klist -k <keytabfile>
kinit:
The kinit command can be used to use a keytab, authenticate to the Kerberos server, and request a ticket. We can use the following command:
kinit <principal name> -k -V -t <keytabfile>
While the -V flag is not really needed, I highly recommend adding it for additional verbosity, such as actually knowing that you are authenticated. Without it, you won't see any useful output.
Start by listing the principals stored in the service's associate keytab and then try to authenticate with the keytab. Use the -V flag for verbose mode to make sure you can see the output.
Now that you are authenticated, we can finally start to interface with the datalake! However, you will soon notice that you don't have access to the CLI tools associated with Hadoop. The simple reason? The compromised user does not have the correct environment paths set to use the Hadoop services. Go find the associated bin directory for the Hadoop services and either add this to your environment path or navigate to this directory to execute the associated Hadoop services.
For starters, we are interested in interfacing with the datalake's file system. Thus, we will make use of the hdfs application. Have a read through this guide to get an understanding of the type of commands you can execute:
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html (opens in new tab) (opens in new tab)
The command that we are specifically interested in is the dfs command, which allows us to run commands on the datalake. Using this command, go hunt down the flag stored in this user's HDFS home directory.
Which directory stores the keytabs for the Hadoop services?
What is the first principal stored in this keytab file?
What is the value of the flag stored in the compromised user's HDFS home directory (flag3.txt)?
Even though we now have access to the datalake, we still have not performed privilege escalation. We will need to do something in order to gain full control of the cluster.
After authenticating to the datalake, things start to get interesting. You see, even though the datalake may look like a normal Unix , in terms of authentication and access control, things work a tad bit different when it comes to Hadoop. One key concept to understand is that your current user and your cluster user, DOES NOT have to correspond. Through , the cluster will believe you are whoever you authenticate as, regardless of your actual user.
Let's verify this concept before starting our exploitation path. Use the -touchz option of HDFS interface to touch a file to the /tmp directory of the datalake. Then, use the -ls option to list the contents of the temp directory and review the permissions associated with that file.
Okay, so what if we impersonate another Hadoop service? Often, the services in Hadoop has to perform impersonation to allow them to perform their duties. The HUE user may have to impersonate the HDFS user to create a new home directory. The Zeppelin user may have to impersonate the YARN user to schedule a job. YARN may impersonate the NodeManager to allocate processes to different nodes.
The secure way of configuring this is to copy keytabs and restrict them down with granular file permissions to only the services that require them. But ain't nobody got time for that. So what organisations usually do is they just chmod the hell (666) out of these keys until the services can impersonate as they deem fit. In our case, our organisation at least tried to perform some key segregation by using group permissions, but it is honestly not that much more secure.
Based on your enumeration results, you should see that our compromised user has access to a number of keytabs from other services, due to being a member of the hadoop_services group. Now the question becomes, which of these users can lead to privilege escalation? Have a look through the group memberships to find the service that sometimes has to act like a normal service, whereas other times it has to invoke its "super" abilities to perform tasks. This will be our target. Impersonate this user and retrieve the flag from its associated HDFS home directory. To verify that you have fully impersonated this user on the datalake, touch another file to the temp directory and review its permissions.
HDFS impersonation is cool and all because we can now access the home directories of other users, but from an perspective, we are still the low-privileged user. We need to find some way to abuse the permissions of this impersonated service to also become this user on an level. Enter MapReduce. Certain Hadoop services, our impersonated service being one of them, have the ability to ask the datalake to execute processes on their behalf. The interesting thing is, these jobs will be executed from the context of the user associated with the job. So what if one of these jobs could be remote code execution? Fun times!
A resource that will greatly assist you at this step is the Hadoop Attack Library:
https://github.com/wavestone-cdt/hadoop-attack-library (opens in new tab)
Option number 5, executing commands, looks like a great place to start. This is where the training wheels come off. Using this attack library, try to create remote code execution job that will drop you from an perspective in the context of the impersonated user. Perhaps start small as the guide suggests, by first just creating a job that recovers a file from disk before going for the shell. Once impersonated, you can recover the flag from this user's home directory.
What is the value of the flag in the impersonated user's HDFS home directory (flag4.txt)?
What is the value of the flag in the impersonated user's OS home directory (flag5.txt)?
Congrats! You were able to impersonate another user!
What's better than a ball of Yarn? Well owning the Yarn farm of course!
Now that we have some more permissions, it is finally time to herd up all the farm animals and take control. There is one peculiar keytab remaining. This keytab belongs to the NodeManager service. This is not a service mentioned at the start since this is a service that you normally never interact with directly. It is a little shy and stays behind the scenes. However, it is truly the master orchestrator. You want to create a new node? Got to speak to the manager. Do you want to update containers? Got to speak to the manager. Do you want to switch to the Secondary NameNode? Got to speak to the manager. Do you want to run a job? Got to speak to the manager.
Essentially, behind the scenes, this service ensures that all nodes are up and running. If a node becomes unhealthy, the NodeManager will inform the relevant services like ResourceManager to distribute the load of that node onto others in order to improve the node's health or get it ready for retirement.
It is usually behind the scenes, as organisations usually make use of what's called Datalake management solutions. These are applications like Ambari or Cloudera manager. These applications provide a centralised platform that helps control, manage, and deploy your cluster. However, they are usually just wrapping the NodeManager and ResourceManager services.
With all of this being said, if you want to ever control the entire cluster, this would be the service to hunt for. Using your newly acquired permissions, try to impersonate the NodeManager service. First just from a datalake perspective, but then also from an perspective.
What is the value of the flag associated with the NodeManager's OS home directory (flag7.txt)?
This service is peculiar. If it can't directly access the other nodes, it probably needs to be able to invoke privileged commands?
You are going to be very disappointed in the root privilege escalation path, but it is as real as it can get. You see, to figure out exactly what commands are required to execute as NodeManager is a massive pain. So painful that large datalake providers often even recommend this glaringly bad misconfiguration. Your next flag awaits you in root's home directory.
What is the value of the flag in the root user's HDFS home directory (flag9.txt)?
So you finally got root! What's better than one root?
We still have not answered that one burning question. How do NodeManager and ResourceManager actually join these nodes together both for storage and processing capabilities?
Yes, what you will find here is a misconfiguration, but try to fix this issue at your own peril through the use of sudo wrappers. It is much simpler to just protect the root user and risk accept the risk. Once you become root on a single node, 99% of the time it is over at this point.
Using basic enumeration from your new rootly position, you should be able to authenticate to the secondary cluster node on 172.23.0.4. Your last flag waits in the root directory on that host.
Congrats! You made it to the end and took control of the entire cluster!
Some worthwhile notes on this lab:
- We cheated a bit here by having a single node in the main cluster. Usually, you would have many nodes. This is actually fairly important since you have no control over which node MapReduce would select for your job. Meaning you would get a randomised shell on node. This can become fairly annoying if you are trying to target a very specific host, but just executing a bunch of jobs will usually allow you to get lucky and hit the node of your choice.
- Although the misconfigurations here were simulated, they replicate the real configuration usually seen when using Ambari as your datalake manager. Ambari can secure your datalake for you, but you have to alter the configuration to allow it to do so.
- A key misconfiguration in datalakes is not setting the appropriate UMASK value for the datalake. This causes all pushed files to be world-readable by default which means you are in for a bad time if you start pushing sensitive content to your cluster.
- Datalakes are often an all-or-nothing thing when they are kerberised but don't have more granular access control. This means that ANY user can actually authenticate to the datalake and read files. This paired with the UMASK misconfiguration makes for a very potent and large attack surface.
- It is not just the data that needs protection in the datalake, but the actual processing resources themselves as well. If you think GPUs are fast at mining Crypto, you haven't seen what a bad actor can do using the distributed computing of a cluster with MapReduce optimising those jobs.
Ready to learn Cyber Security?
TryHackMe provides free online cyber security training to secure jobs & upskill through a fun, interactive learning environment.
Already have an account? Log in